(Designing Machine Learning Systems 的作者)
The best practices for deploying traditional machine learning appli‐ cations—systematic experimentation, rigorous evaluation, relentless optimization for faster and cheaper models—are still the best practices for working with foundation model-based applications.
——- Preface ———-
-
作者用来判断什么技术是基础的、持久的:
-
- determine whether it results from the fundamental limitations of how AI works or if it’ll go away with better models
-
consulted an extensive network of researchers and engineers
-
Lindy’s law: the future life expectancy of a technology is proportional to its current age
-
一些基础概念
-
probabilistic concepts: sampling, determinism, distribution
-
ML concepts: supervision, self-supervision, log-likelihood, gradient descent, backpropagation, loss function , hyperparameter tuning
-
various neural network architectures: feedforward, recurrent, and transformer
-
Metrics: accuracy, F1, precision, recall, consine similarity, cross entropy
-
the quality of a model’s response depends on the following aspects (outside of the model’s generation setting):
-
The instructions for how the model should behave
-
The context the model can use to respond to the query
-
The model itself
Chapter 1 Introduction
From language models to large language models
-
tokenization: a token can be a character, a word, or a part of a word, depending on the model. For GPT-4, an average token is approximately 3/4 the length of a word
-
vocabulary size: the number of distinct words constructed by all the tokens
-
why do language models use token as unit instead of word or character?
-
Compared to characters, tokens allow the model to break words into meaningful components. e.g. cooking — cook + ing
-
there are fewer unique tokens than unique words — reduce the model’s vocabulary size, making the model more efficient
-
help the model process unknown words
-
Two main types of language models
-
masked language models: 训练方式为句子填空
-
e.g. BERT (bidirectional encoder representations from trasformers)
-
commonly used for non-generative tasks. e.g. sentiment analysis / text classification
-
also useful for tasks requireing an understanding of the overall context. e.g. code debugging
-
autoregressive language models: 训练预测下一个 token
-
text generation, 因此现在更为流行
-
self-supervision 的特性使语言模型(相比物体识别、推荐系统等其他模型)成为 scaling approach 的中心,它们的训练不依赖于 labeled data
-
In self-supervision, instead of requiring explicit labels, the model can infer labels from the input data. Language modeling is self-supervised because each input sequence provides both the labels (tokens to be predicted) and the contexts the model can use to predict these labels.
From large language models to foundation models
-
a multimodal model generates the next token conditioned on both text and image tokens, or whichever modalities that the model supports
-
self-supervision works for multimodal models too
-
CLIP (openai, 2021) — natural language supervision
-
using (image, text) pairs co-occurred on the internet
-
CLIP is an embedding model instead of a generative model
-
Multimodal embedding models like CLIP are the back‐ bones of generative multimodal models, such as Flamingo, LLaVA, and Gemini
Planning AI Applications
“One of my favorite things to daydrem about is the different application I can build. However, not all applications should be built” ; “It’s easy to build a cool demo with foundation models. It’s hard to create a profitable product.” — 怎么决定什么 AI applications 值得做
-
the role of AI and humans in the applications
-
In AI, there are generally three types of competitive advantages: technology, data, and distribution—the ability to bring your product in front of users. With foundation models, the core technologies of most companies will be similar. The distribution advantage likely belongs to big companies.The data advantage is more nuance
Usefulness thresholds might include the following metrics groups:
-
Quality metrics to measure the quality of the chatbot’s responses.
-
Latency metrics including TTFT (time to first token), TPOT (time per output token), and total latency. What is considered acceptable latency depends on your use case. If all of your customer requests are currently being processed by humans with a median response time of an hour, anything faster than this might be good enough.
-
Cost metrics: how much it costs per inference request.
-
Other metrics such as interpretability and fairnes
Milestone Planning
- Planning an AI product needs to account for its last mile challenge. Initial success with foundation models can be misleading. It might take a weekend to build a demo but months, and even years, to build a product.
Maintenance
As each model has its quirks, strengths, and weaknesses, developers working with the new model will need to adjust their workflows, prompts, and data to this new model. Without proper infrastructure for versioning and evaluation in place, the process can cause a lot of headaches.
—— AI Stack ——
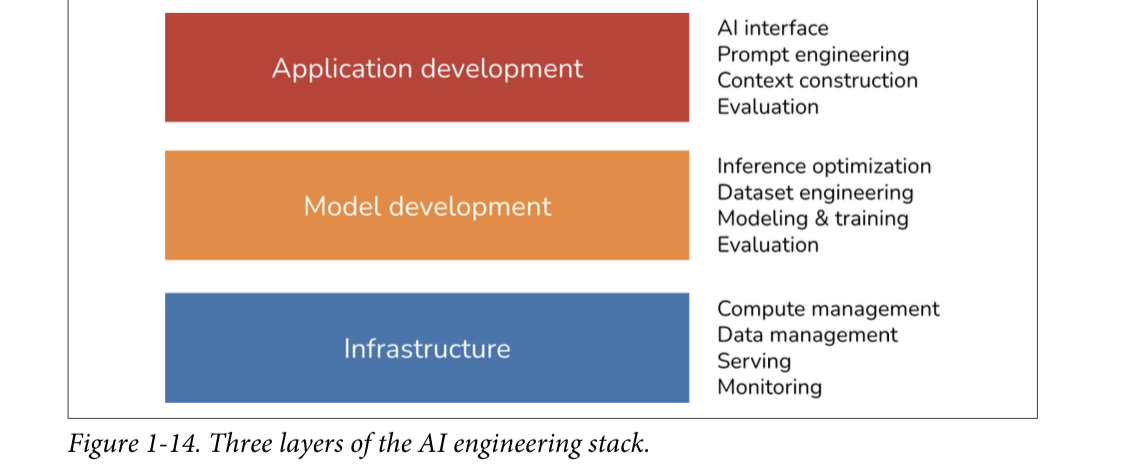
Three layers of the AI stack
-
Application development
-
providing a model with good prompts and necessary context
-
rigorous evaluation
-
good interfaces
-
Model development
-
modeling and training
-
tools: tensorflow, transformers, PyTorch
-
pre-training, finetuning, post-training
-
pre-training: training a model from scratch (model weights are randomly initialized)
-
post-training: 和 finetuning 一个阶段,不过通常指 done by model developers, finetuning 通常 done by application developers
-
data engineering
-
In traditional ML engineering, most use cases are close-ended—a model’s output can only be among predefined values. Foundation models are open-ended
-
traditional ML engineering works more with tabular data, whereas foundation models work with unstructured data
-
In AI engineering, data manipulation is more about deduplication, tokenization, context retrieval, and quality control (ML 更关注 feature engineering)
-
inference optimization: making models faster and cheaper
-
Infrastructure
-
model serving, managing data
-
compute
-
monitoring
AI engineering VS ML engineering
-
AI engineering differs from ML engineering in that it’s less about model development and more about adapting and evaluating models.
-
Model adaption, two categories, depending on whether they require updating model weights
-
prompt-based techiniques, adapting a model by giving it instructions and context
-
finetuning
Chapter 2 Understanding Foundation Models
Differences in foundation models can be traced back to decisions about training data, model architecture and size, and how they are post-trained to align with human preferences.
Training Data
- common source for training data: common crawl - > colossal clean crawled corpus(C4 for short)
- domain distribution
- business & industrial 16%
- technology 15%
- news & media 13%
- arts & entertainment 11%
- science & health 9%
- hobbies & leisure 8%
- jobs & education 7%
- home & garden 6%
- travel 6%
- community 5%
- law & government 4%
- different performance on different languages
- you can infer a model’s domain from its benchmark performance
Modeling
model architecture
transformer architecture, based on attention mechanism
-
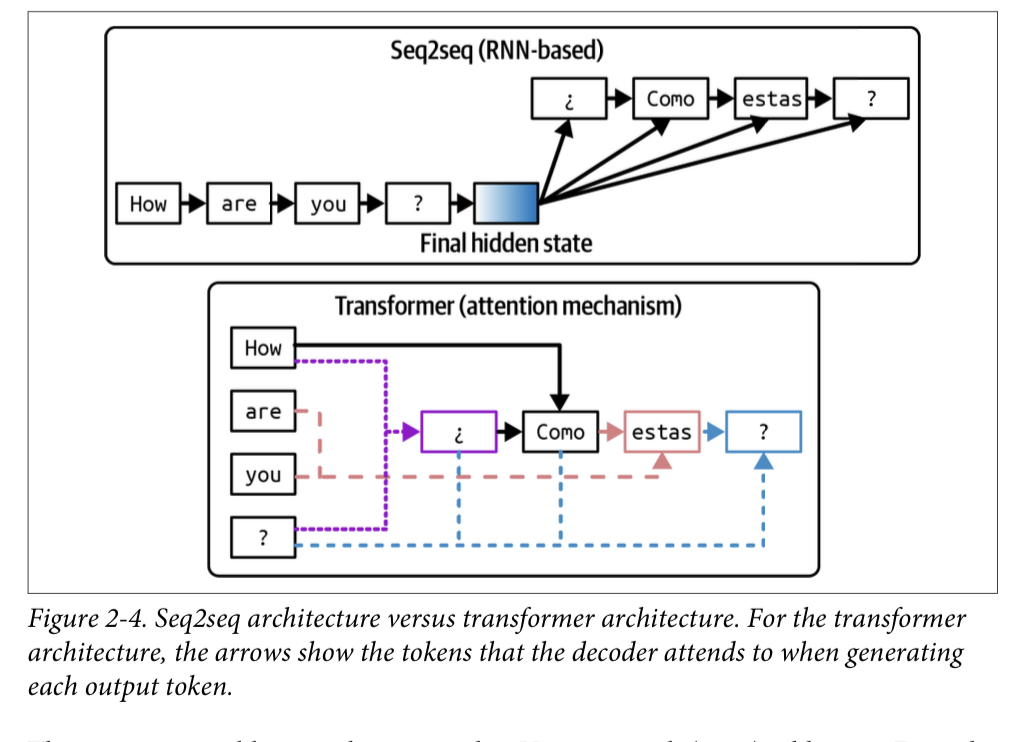
seq2seq architecture
-
use RNNs as its encoder and decoder: the encoder processes the input tokens sequentially, outputting the final hidden state that represents the input. The decoder then generates output tokens sequentially, conditioned on both the final hidden state of the input and the previously generated token
-
problems
-
decoder generates output tokens using only the final hidden state of the input
-
the RNN encoder and decoder mean that both input processing and output generation are done sequentially, making it slow for long sequences
-
Transformer architecture addresses the problems of seq2seq architecture with the attention mechanism
-
The attention mechanism allows the model to weigh the importance of different input tokens when generating each output token. This is like generating answers by referencing any page in the book
-
the input tokens can be processed in parallel, while still have the sequential output bottleneck
-
Two steps of inference for transformer-based language models
-
prefill: processes the input tokens in parallel. This step creates the intermediate state necessary to generate the first output token. This intermediate state includes the key and value vectors for all input token
-
decode: generate one output token at a time
-
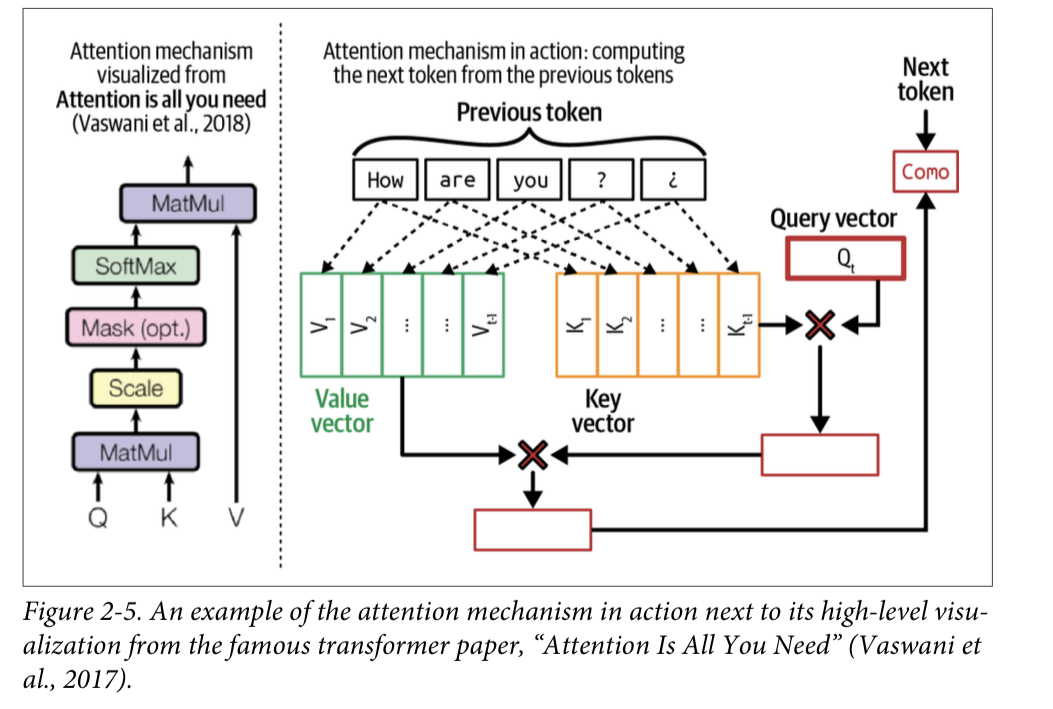
Attention mechanism: key, value, query vectors
-
query vector(Q): the current state of the decoder at each decoding step —- the person looking for information to create a summary
-
key vector(K): a previous token (input tokens and previously generated tokens)—- the page number
-
value vector(V): the actual value of a previous token — the page content
-
Attention mechanism computes how much attention to give an input token by performing a dot product between the query vector and its key vector. A high score means that the model will use more of that page’s content (its value vector) when generating the book’s summary
model size
Post-Training
- supervised finetuning
- preference finetuning
sampling