“evals are surprisingly often all you need.” --- Greg Brockman, an OpenAI cofounder
基础理论
摘自 AI Engineering - Building applications with foundation models
Entropy, Cross entropy, Perplexity, BPC, and BPB
Entropy measures how much information, on average, a token carries. The higher the entropy, the more information each token carries, and the more bits are needed to represent a token. Intuitively, entropy measures how difficult it is to predict what comes next in a language. The lower a language’s entropy (the less information a token of a language carries), the more predictable that language.
Cross Entropy A language model’s cross entropy on a dataset measures how difficult it is for the language model to predict what comes next in this dataset. A model’s cross entropy on the training data depends on two qualities:
- The training data’s predictability, measured by the training data’s entropy
- How the distribution captured by the language model diverges from the true distribution of the training data A language model is trained to minimize its cross entropy with respect to the training data. H(P,Q)=H(P)+D_KL (P| |Q) H: entropy, P: the true distribution of the training data, Q: the distribution learned by the language model, D_KL(P || Q): The divergence of Q with respect to P can be measured using the Kullback–Leibler (KL) divergence
Bits-per-Character(BPC) and Bits-per-Byte(BPB) The number of bits per token isn’t comparable across models: 模型 tokenizer 不一样,划分粒度不同。 One complication with BPC arises from different character encoding schemes. For example, with ASCII, each character is encoded using 7 bits, but with UTF-8, a character can be encoded using anywhere between 8 and 32 bits. A more standardized metric would be bits-per-byte (BPB), the number of bits a language model needs to represent one byte of the original training data.
Cross entropy tells us how efficient a language model will be at compressing text. If the BPB of a language model is 3.43, meaning it can represent each original byte (8 bits) using 3.43 bits, this language model can compress the original training text to less than half the text’s original size.
Perplexity(shortened to PPL):
- PPL(P,Q)=2^H(P,Q) (using bit as the unit for entropy and cross entropy, each bit can represent 2 unique values, hence the base of 2 in the preceding perplexity equation.); PPL(P,Q)=e^H(P,Q)(using nat (natural log) as the unit for entropy and cross entropy, including Pytorch, Tensorflow)
- If cross entropy measures how difficult it is for a model to predict the next token, perplexity measures the amount of uncertainty it has when predicting the next token. Higher uncertainty means there are more possible options for the next token. The more uncertainty the model has in predicting what comes next in a given dataset, the higher the perplexity.
- Some Rules
- More structured data gives lower expected perplexity
- The bigger the vocabulary, the higher the perplexity
- The longer the context length, the lower the perplexity
- Post- training is about teaching models how to complete tasks. As a model gets better at completing tasks, it might get worse at predict‐ ing the next tokens. A language model’s perplexity typically increa‐ ses after post-training. Some people say that post-training collapses entropy.
- Perplexity 的应用
- For a given model, perplexity is the lowest for texts that the model has seen and memorized during training. Therefore, perplexity can be used to detect whether a text was in a model’s training data. This is useful for detecting data contamination—if a model’s perplexity on a benchmark’s data is low, this benchmark was likely included in the model’s training data, making the model’s performance on this benchmark less trustworthy.
- This can also be used for deduplication of training data: e.g., add new data to the existing training dataset only if the perplexity of the new data is high.
- Perplexity is the highest for unpredictable texts, such as texts expressing unusual ideas (like “my dog teaches quantum physics in his free time”) or gibberish (like “home cat go eye”). Therefore, perplexity can be used to detect abnormal texts.
Exact Evaluation
- Exact evaluation vs Subjective evaluation. Focuses on open-ended evaluation because close-ended evaluation is already well understood.
- Functional correctness
- Evaluating a system based on whether it performs the intended functionality.
- Code generation is an example of a task where functional correctness measurement can be automated. Functional correctness in coding is sometimes execution accuracy.
- A benchmark problem comes with a set of test cases. Each test case consists of a sce‐ nario the code should run and the expected output for that scenario.
- e.g. OpenAI’s HumanEval and Google’s MBPP (Mostly Basic Python Problems Dataset)
- pass@k: A model solves a problem if any of the k code samples it generated pass all of that problem’s test cases. The final score, called pass@k, is the fraction of the solved problems out of all problems.
- A benchmark problem comes with a set of test cases. Each test case consists of a sce‐ nario the code should run and the expected output for that scenario.
- Another category of tasks whose functional correctness can be automatically evaluated is game bots.
- Tasks with measurable objectives can typically be evaluated using functional correctness.
- Similarity measurements against reference data
- If the task you care about can’t be automatically evaluated using functional correct‐ ness, one common approach is to evaluate AI’s outputs against reference data.
- e.g. translation tasks
- Since this evaluation approach requires reference data, it’s bottlenecked by how much and how fast reference data can be generated. Reference data is generated typically by humans and increasingly by AIs.
- There are four ways to measure the similarity between two open-ended texts:
- Asking an evaluator to make the judgment whether two texts are the same
- Exact match: whether the generated response matches one of the reference responses exactly
- Lexical similarity: how similar the generated response looks to the reference responses
- approximate string matching/ fuzzy matching: edit distance
- n-gram similarity
- Common metrics for lexical similarity are BLEU, ROUGE, METEOR++, TER, and CIDEr.
- Since the rise of foundation models, fewer benchmarks use lexical similarity.
- Semantic similarity: how close the generated response is to the reference responses in meaning (semantics)
- embedding similarity
- cosine similarity
- the reliability of semantic similarity depends on the quality of the underlying embedding algorithm
- embedding similarity
- Two responses can be compared by human evaluators/hand-designed metrics or AI evaluators.
- If the task you care about can’t be automatically evaluated using functional correct‐ ness, one common approach is to evaluate AI’s outputs against reference data.
AI as a judge
- Evaluate the quality of a response by itself, given the original question:
“Given the following question and answer, evaluate how good the answer is for the question. Use the score from 1 to 5.
- 1 means very bad.
- 5 means very good.
Question: [QUESTION]
Answer: [ANSWER]
Score:”
- Compare a generated response to a reference response to evaluate whether the generated response is the same as the reference response. This can be an alterna‐ tive approach to human-designed similarity measurements:
“Given the following question, reference answer, and generated answer, evaluate whether this generated answer is the same as the reference answer.
Output True or False.
Question: [QUESTION]
Reference answer: [REFERENCE ANSWER]
Generated answer: [GENERATED ANSWER]”
- Compare two generated responses and determine which one is better or predict which one users will likely prefer. This is helpful for generating preference data for post-training alignment (discussed in Chapter 2), test-time compute (dis‐ cussed in Chapter 2), and ranking models using comparative evaluation (dis‐ cussed in the next section):
“Given the following question and two answers, evaluate which answer is better. Output A or B.
Question: [QUESTION]
A: [FIRST ANSWER]
B: [SECOND ANSWER]
The better answer is:”
- In general, a judge’s prompt should clearly explain the following:
- The task the model is to perform, such as to evaluate the relevance between a generated answer and the question.
- The criteria the model should follow to evaluate, such as “Your primary focus should be on determining whether the generated answer contains sufficient information to address the given question according to the ground truth answer”. The more detailed the instruction, the better.
- The scoring system, which can be one of these:
- Classification, such as good/bad or relevant/irrelevant/neutral.
- Discrete numerical values, such as 1 to 5. Discrete numerical values can be considered a special case of classification, where each class has a numerical interpretation instead of a semantic interpretation.
- Continuous numerical values, such as between 0 and 1, e.g., when you want to evaluate the degree of similarity.
- Tips
- Language models are generally better with text than with numbers. It’s been reported that AI judges work better with classification than with numerical scoring systems.
- For numerical scoring systems, discrete scoring seems to work bet‐ ter than continuous scoring. Empirically, the wider the range for discrete scoring, the worse the model seems to get. Typical discrete scoring systems are between 1 and 5.
- Prompts with examples have been shown to perform better.
Ranking Models with Comparative Evaluation
- For each request, two or more models are selected to respond. An evaluator, which can be human or AI, picks the winner. Many developers allow for ties to avoid a winner being picked at random when drafts are equally good or bad.
- not all questions should be answered by preference. Many questions should be answered by correctness instead. When collecting comparative feedback from users, one challenge is to determine what questions can be determined by preference voting and what shouldn’t be.
- The more models there are, the more challenging ranking becomes. Given comparative signals, a rating algorithm is then used to compute a ranking of models. Typically, this algorithm first computes a score for each model from the comparative signals and then ranks models by their scores.
- model ranking is a predictive problem. We compute a ranking from historical match outcomes and use it to predict future match outcomes.
- Ranking algorithms typically assume transitivity. If model A ranks higher than B, and B ranks higher than C, then with transitivity, you can infer that A ranks higher than C. --- However, it’s unclear if this transitivity assumption holds for AI models.
- An efficient matching algorithm should sample matches that reduce the most uncertainty in the overall ranking.
- Both comparative evaluation and the post-training alignment process need preference signals, which are expensive to collect. This motivated the development of preference models: specialized AI judges that predict which response users prefer.
- Comparative evaluation can give us discriminating signals about models that can’t be obtained otherwise. For offline evaluation, it can be a great addition to evaluation benchmarks. For online evaluation, it can be complementary to A/B testing.
- It’s easier to compare two out‐ puts than to give each output a concrete score. As models become stronger, surpass‐ ing human performance, it might become impossible for human evaluators to give model responses concrete scores. However, human evaluators might still be able to detect the difference, and comparative evaluation might remain the only option; comparative evaluation aims to capture the quality we care about: human preference. It reduces the pressure to have to constantly create more benchmarks to catch up with AI’s ever-expanding capabilities.
Evaluate AI Systems
Evaluation criteria
Evaluation-driven development: defining evaluation criteria before building.
- “The most common enterprise applications in production are those with clear evaluation criteria. We might be missing out on many potentially game- changing applications because there is no easy way to evaluate them. I believe that evaluation is the biggest bottleneck to AI adoption. Being able to build reliable evaluation pipelines will unlock many new applications.”
- Domain- specific capability
- A model’s domain-specific capabilities are constrained by its configuration (such as model architecture and size) and training data.
- domain- specific benchmarks
- Domain-specific capabilities are commonly evaluated using exact evaluation.
- A multiple-choice question (MCQ) might have one or more correct answers. A common metric is accuracy. Metrics for classifi‐ cation tasks, other than accuracy, include F1 scores, precision, and recall.
- MCQs are popular because they are easy to create, verify, and evaluate against the random baseline.
- A drawback of using MCQs is that a model’s performance on MCQs can vary with small changes in how the questions and the options are presented.
- MCQs are best suited for evaluating knowledge (“does the model know that Paris is the capital of France?”) and reasoning (“can the model infer from a table of business expenses which department is spending the most?”). They aren’t ideal for evaluating generation capabilities such as summarization, translation, and essay writing.
- Generation capability
- 大语言模型之前,NLG 会使用 fluency 和 coherence,但现在大语言模型基本上这上面表现都不错
- Factual consistency
- Local factual consistency:The output is evaluated against a context. The output is considered factually con‐ sistent if it’s supported by the given context.
- e.g. summarization (the summary should be consistent with the original document), cus‐ tomer support chatbots (the chatbot’s responses should be consistent with the company’s policies), and business analysis (the extracted insights should be con‐ sistent with the data
- Global factual consistency: The output is evaluated against open knowledge.
- Global factual consistency is important for tasks with broad scopes such as general chatbots, fact-checking, market research, etc.
- Often, the hardest part of factual consistency verification is determining what the facts are.
- When designing metrics to measure hallucinations, it’s important to analyze the model’s outputs to understand the types of queries that it is more likely to hallucinate on. Your benchmark should focus more on these queries. For example, the queries that involve niche knowledge and queries asking for things that don’t exist.
- Evaluate approach:
- AI as judge:
Factual Consistency: Does the summary untruthful or misleading facts that are not supported by the source text? Source Text:{{Document}} Summary: {{Summary}} Does the summary contain factual inconsistency? Answer: - Self-verification: relies on an assumption that if a model generates multiple outputs that disagree with one another, the original output is likely hallucinated. Given a response R to evaluate, SelfCheckGPT generates N new responses and measures how consistent R is with respect to these N new responses.
- Knowledge-augmented verification:SAFE, Search-Augmented Factuality Evaluator
- Use an AI model to decompose the response into individual statements.
- Revise each statement to make it self-contained. For example, the “it” in the statement “It opened in the 20th century” should be changed to the original subject.
- For each statement, propose fact-checking queries to send to a Google Search API.
- Use AI to determine whether the statement is consistent with the research results.
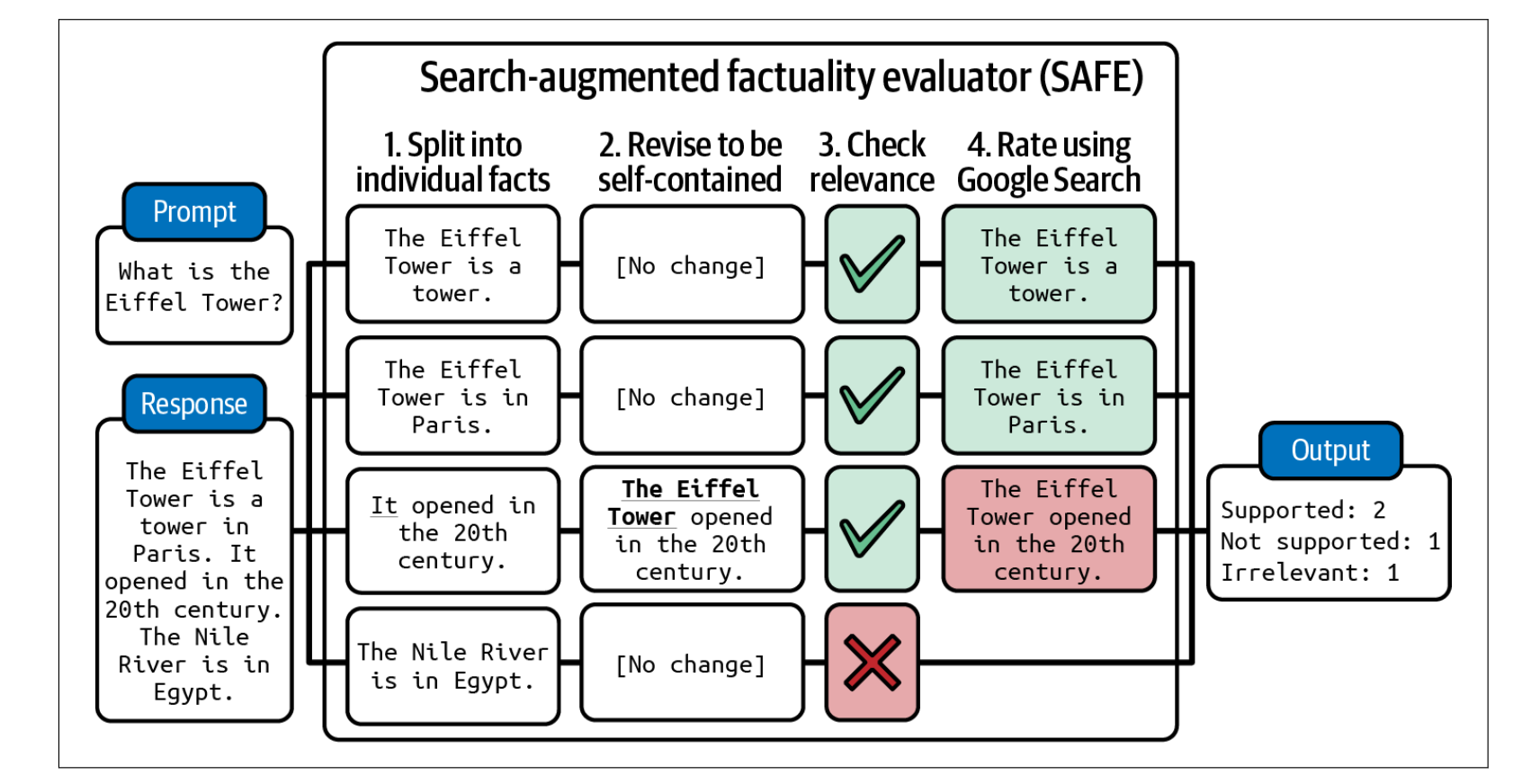
- AI as judge:
- Verifying whether a statement is consistent with a given context can also be framed as textual entailment, which is a long-standing NLP task. Given a premise (context), it determines which category a hypothesis (the output or part of the output) falls into:
- Entailment: the hypothesis can be inferred from the premise.
- Contradiction: the hypothesis contradicts the premise.
- Neutral: the premise neither entails nor contradicts the hypothesis.
- Instead of using general-purpose AI judges, you can train scorers specialized in factual consistency prediction. e.g. TruthfulQA
- Factual consistency is a crucial evaluation criteria for RAG, retrieval-augmented generation, systems. Given a query, a RAG system retrieves relevant information from external databases to supplement the model’s context.
- Local factual consistency:The output is evaluated against a context. The output is considered factually con‐ sistent if it’s supported by the given context.
- Instruction-following capability
- Instruction-following capability is essential for applications that require structured outputs, such as in JSON format or matching a regular expression (regex)
- Instruction-following criteria
- IFEval, Instruction-Following Evaluation, Google: evaluate whether the model can produce outputs following an expected format
- identified 25 types of instructions that can be automatically verified, such as keyword inclusion, length constraints, number of bullet points, and JSON format.
- 使用程序检测
- INFOBench
- On top of evaluating a model’s ability to follow an expected format like IFEval does, INFOBench also evaluates the model’s ability to follow content constraints (such as “discuss only climate change”), linguistic guide‐ lines (such as “use Victorian English”), and style rules (such as “use a respectful tone”).
- For verification, INFOBench authors constructed a list of criteria for each instruction, each framed as a yes/no question.
- You should curate your own benchmark to evaluate your model’s capability to follow your instructions using your own criteria.
- One of the most common types of real-world instructions is roleplaying. Benchmarks to evaluate roleplaying capability include RoleLLM and CharacterEval
- CharacterEval used human annotators and trained a reward model to evaluate each roleplaying aspect on a five-point scale.
- RoleLLM evaluates a model’s ability to emulate a persona using both carefully crafted similarity scores (how similar the generated outputs are to the expected outputs) and AI judges.
- IFEval, Instruction-Following Evaluation, Google: evaluate whether the model can produce outputs following an expected format
- Cost and latency metrics
- metrics for latency: time to first token, time per token, time between tokens, time per query etc.
- Latency depends not only on the underlying model but also on each prompt and sampling variables. Autoregressive language models typically generate outputs token by token. The more tokens it has to generate, the higher the total latency.
- Model Selection
- In general, the selection process for each technique typically involves two steps:
- Figuring out the best achievable performance
- Mapping models along the cost–performance axes and choosing the model that gives the best performance for your bucks
-
Model Selection Workflow
- In general, the selection process for each technique typically involves two steps:
应用部分
Benchmark 不能完全代表模型在用户实际业务场景上的表现,需要设计针对自己业务场景设计的评测。 同时大模型评测除了针对模型本身,也可以面向整个模型应用进行评测,覆盖RAG、MCP、工作流等构成的统一整体进行端到端的测试。
评测需求分析
评测集
- 用户最常见的使用大模型都会分哪几种场景,这些场景的调用量分布是怎么样的?
- 每个场景里大模型的输入输出是怎么样的,分别提供一些示例。
评价维度
- 如何判断大模型效果好不好?业务人员会关注哪些维度?
- 针对其中的每个维度,是如何评估的,是定性的对错,还是有打分的机制。如果是打分,分别打几分。每个档次之间的评分标准是什么。
- 对于多维度的评价,是否可以通过一个公式(比如通过加权)将结果量化成一个数字,还是必须每个维度分别分析?
模型效果
- 当前大模型的实际效果表现如何?这些效果评估是来自哪里?是感性的反馈还是有数字支撑。
- 当前系统如何收集用户的bad case,是否有日志可以分析?
- 当前都有哪些原因可能导致bad case,都是什么样的原因?
- 是否分析过bad case,都是哪些原因导致结果不满意,分布如何。
评测集设计
- 端到端评测集
- 实际场景效果:历史记录 — 离线数据集;接入线上流量进行“双跑” — 在线数据集
- 特定子场景效果:定义特定场景并设计对应的评测集。
- 分层评测集
- bad case回归:使用线上问题中的用户的负面反馈,或者在测试、质检等环节形成的案例,经过标注形成Bad Case作为评测集。目的是为了验证优化工作对bad case的优化效果。
- 功能模块评测:比如评测模型应用中的意图识别模块的准确率、知识库部分的召回准确率等
- 安全评测集:一般由风控和安全团队提供
评测集需要持续优化机制:
- 基于过程中的bad case持续优化评测集,通过删除过程中发现的低质量的评测集样本,补充优质样本,或对业务的新增场景以及评测集数量比较少的小场景补充样本等方式,持续完善评测集。
- 如果是通过大模型自动生成的评测集,则不只是优化评测集,也需要根据不合理的部分优化提示词,以生成更高质量的评测集。
评测维度设计
对于生成类场景,由于没有标准答案,需要业务人员根据场景设计评测维度。比如翻译场景,“信、达、雅”是最经典的三个标准。
- 模型是否有统一的评价维度,还是需要从多个维度去判断模型的能力。
- 对于具体的某个维度,分几档(量级)。
- 每个量级的定义,以及区分不同量级的标准。 模型效果量化:根据各维度分数,得到一个总分 评测类型:单个评测VS对比评测
大模型应用的分功能模块评测
Model evaluation must match the system
- RAG:Focused on retrieval and context grounding
- Metrics:
- Context Precision (RAGAS)
- Faithfulness Score
- Metrics:
- Agents:Tool use and multi-step consistency
- Metrics:
- Function call validity rate
- Step consistency / reproducibility
- Metrics:
- MCP Systems:Structured doc inputs and complex flow eval
- Metrics:
- Field extraction accuracy
- Pipeline completion rate
- Metrics:
- Decision Support:User-aligned, judgment-heavy outputs
- Metrics:
- Field extraction accuracy
- Pipeline completion rate
- Metrics:
“evals are surprisingly often all you need.”
对 bad case 进行系统性分析
重点阅读 Building eval systems that improve your AI product
多轮任务的评测
一些讨论
参考: