1. 记忆的概念与分类
记忆 vs RAG vs Context Engineering
三者常被混淆,但定位不同:
| 维度 | Agent 记忆 | RAG | Context Engineering |
|---|---|---|---|
| 核心目标 | 个性化、持续进化、跨会话连续性 | 大规模知识的事实检索 | 单次推理中组织最优上下文 |
| 数据来源 | 交互历史、用户行为、任务经验 | 外部知识库、文档 | 系统指令、工具结果、对话历史 |
| 生命周期 | 跨会话持久,需主动管理(更新、遗忘) | 静态或周期性更新 | 单次请求内,用完即弃 |
| 关键区别 | 需要 formation → evolution → retrieval 的全生命周期 | 主要是 index → retrieve → generate | 主要是 prompt 工程和上下文窗口管理 |
记忆的本质是让 agent 具备持续进化能力——不只是检索答案,而是参与推理过程,影响决策和行为。
FFD 分类框架
论文 Memory in the Age of AI Agents 提出了 Forms-Functions-Dynamics (FFD) 三维分类框架,比传统的「短期/长期」二分法更细粒度:
1.1 Forms(形态):记忆「长什么样」
Token-level 记忆——以自然语言 token 序列存储
| 类型 | 结构 | 典型实现 | 适用场景 |
|---|---|---|---|
| 1D Flat | 平铺文本列表 | Mem0 的记忆条目、MemGPT 的 recall storage | 简单对话记忆、用户偏好 |
| 2D Planar/Graph | 图结构、知识图谱 | A-Mem 的自组织图、AriGraph、Zep 的三层时序图 | 实体关系推理、复杂世界建模 |
| 3D Hierarchical | 多层级树状结构 | MemTree、Generative Agents 的 reflection tree | 长期叙事保持、多粒度检索 |
Parametric 记忆——编码进模型参数
| 类型 | 方式 | 示例 |
|---|---|---|
| Internal(权重编辑) | 直接修改模型权重 | ROME、MEMIT、Deepseek Engram |
| External(外挂适配器) | 外接 LoRA/Adapter | MemLoRA、TAIA |
Latent 记忆——KV cache 层面的隐式表示
- Generate:将长上下文压缩为少量 memory token(如 Gist tokens、AutoCompressors)
- Reuse:跨会话复用 KV cache(如 InfiniAttention)
- Transform:动态编辑/淘汰 KV cache 条目(如 PyramidKV、SnapKV)
工程直觉:大多数 agent 应用当前以 Token-level 记忆为主(实现简单、可解释),Parametric 和 Latent 记忆是研究前沿,代表记忆从「外部硬盘」向「内化能力」的演进。
1.2 Functions(功能):记忆「用来干什么」
超越传统的语义/情景/程序三分法,按实际功能分类:
事实记忆(Factual Memory)——存储”知道什么”
- 用户事实:用户画像、偏好、历史行为(如 Memobase 的 profile、ChatGPT Memory)
- 环境事实:世界状态、任务环境信息(如 Voyager 的地图数据)
经验记忆(Experiential Memory)——存储”怎么做过”
| 类型 | 存储内容 | 典型应用 |
|---|---|---|
| Case-based | 完整的 episode 轨迹 | Generative Agents 的 memory stream、少样本学习 |
| Strategy-based | 提炼后的策略和反思 | Reflexion、ExpeL 的经验总结 |
| Skill-based | 可复用的代码/工具 | Voyager 的 skill library、JARVIS-1 |
| Hybrid | 混合以上多种 | AgentTrek、STILL-ALIVE |
工作记忆(Working Memory)——存储”正在做什么”
- 单轮:上下文压缩、摘要(如 LLMLingua、Selective Context)
- 多轮:状态整合、层级折叠、认知规划(如 MemGPT 的 main_context、A2A 协议中的 task state)
1.3 Agent Memory vs User Memory
| User Memory | Agent Memory | |
|---|---|---|
| 内容 | 用户画像、偏好、关键事件、应用场景数据 | 技能积累、系统指令、工作流程、错误日志 |
| 目的 | 个性化服务、连续体验 | agent 自我进化、持续学习 |
| 生命周期 | 跟随用户,跨 agent 可迁移 | 跟随 agent 实例,可能共享 |
2. 技术层
2.1 记忆动力学:Formation → Evolution → Retrieval
Memory Formation(记忆形成)
五种形成方式,复杂度递增:
| 方式 | 机制 | 示例 | 适用场景 |
|---|---|---|---|
| Semantic Summarization | LLM 直接提取/摘要 | Mem0、MemGPT 的递归摘要 | 最常见,大多数框架的默认方式 |
| Knowledge Distillation | 从经验中蒸馏策略/规则 | ExpeL 从轨迹中提取 insights | agent 自我改进 |
| Structured Construction | 构建图/表等结构化表示 | A-Mem 自组织图、Zep 的时序知识图谱 | 需要关系推理的场景 |
| Latent Representation | 压缩为连续向量/token | Gist tokens、MemGen 的 memory trigger | 模型级优化 |
| Parametric Internalization | 写入模型参数 | LoRA 微调、ROME/MEMIT 知识编辑 | 长期固化知识 |
摘要方式的两种范式:
- 增量式(Incremental):逐步将新信息融入已有摘要(Mem0、MemGPT)。早期依赖 LLM 的原生摘要能力,后来 Mem1、MemAgent 通过 PPO/GRPO 强化学习优化摘要质量
- 分区式(Partitioned):将信息按语义/时间分片独立摘要再聚合(ReadAgent、LightMem)。效率更高但可能丢失跨分片的语义依赖
触发时机:
- 即时(Hot Path):每轮对话后立即提取,延迟敏感但可能产生噪声
- 延迟(Background):异步处理,对话结束或话题切换时批量提取
- 批量(Batch):定时任务,适合大规模数据处理(如 Memobase 的 buffer-flush 模式,1024 tokens 或 1 小时空闲后批量处理,token 成本降 40-50%)
Memory Evolution(记忆演化)
记忆不是写入后就不变的,需要持续演化:
整合(Consolidation)
| 粒度 | 机制 | 示例 |
|---|---|---|
| 局部整合 | 检索 top-K 相似记忆,LLM 判断是否合并 | RMM、MemGPT |
| 聚类融合 | 跨记忆聚类,融合为更高阶推理单元 | PREMem、TiM |
| 全局整合 | 将新信息整合进全局摘要/画像 | MOOM、Matrix |
更新(Updating)
演进路径:规则替换 → 时间感知软删除 → 延迟一致性 → RL 驱动策略
- 早期:MemGPT、Mem0 通过 LLM 检测冲突后直接 replace/delete——简单但丢失历史上下文
- 改进:Zep 引入时间标注,冲突事实标记
invalid_at而非删除,保持时间完整性 - 双阶段:MOOM、LightMem 采用在线软更新 + 离线反思整合的双阶段策略
- RL 驱动:Mem-α 将记忆更新建模为策略学习问题,LLM 自主学习何时/如何更新
遗忘(Forgetting)
| 策略 | 机制 | 示例 |
|---|---|---|
| 基于时间 | 创建时间衰减,模拟自然遗忘 | MemGPT 驱逐最早消息、MAICC 权重衰减 |
| 基于频率 | 保留高频访问,淘汰低频 | XMem 的 LFU、MemOS 的 LRU |
| 基于重要性 | 综合时间+频率+语义信号评估价值 | Zhong et al. 复合评分、Livia 情感显著性 |
注意:长尾知识虽然访问频率低但可能至关重要,因此很多系统选择不直接删除,而是降权或归档。
Memory Retrieval(记忆检索)
四阶段流水线:
1. 触发时机/意图识别 → 2. 查询构建 → 3. 检索策略 → 4. 后处理
1. 触发时机
- 被动触发:每轮对话自动检索(简单但有噪声)
- 主动触发:agent 自主判断何时需要记忆(如 MemGPT 的 tool call 触发)
- 快慢思考:先快速回答,评估不充分时再触发深度检索(ComoRAG、PRIME)
- 可学习触发:MemGen 从 latent 状态检测关键检索时刻
2. 查询构建
- 查询分解:将复杂问题拆分为子查询,分别检索再聚合(Visconde、ChemAgent)
- 查询改写:LLM 重写原始查询或生成假设文档对齐检索语义(HyDE、MemoRAG)
- 层级路由:H-MEM 的粗到细路由,从领域层逐步缩小到具体记忆层
3. 检索策略
- 语义检索(embedding 相似度)——大多数框架的默认选择
- 词法检索(BM25、TF-IDF)——精确匹配场景
- 图检索(子图遍历、PageRank)——多跳推理(AriGraph、HippoRAG、Zep)
- 混合检索——结合多种信号(Zep 用 RRF 融合 cosine + BM25 + BFS)
4. 后处理
- Re-ranking:语义锚定、角色相关性、时序约束过滤(Semantic Anchoring、Zep 的时间窗口过滤)
- 聚合压缩:将碎片化的检索结果整合为紧凑上下文(ComoRAG 的 Integration Agent)
2.2 记忆存储架构
常见存储模式:
| 模式 | 结构 | 优势 | 劣势 | 典型用途 |
|---|---|---|---|---|
| Collections(集合) | 向量数据库中的记忆条目 | 灵活,易扩展 | 缺乏结构,冗余多 | Mem0、LangMem |
| Profiles(档案) | 结构化 JSON/Schema | 高精度,SQL 查询 <100ms | Schema 需预定义 | Memobase |
| Graph(图) | 知识图谱/实体关系 | 关系推理、多跳查询 | 构建复杂 | Zep、Cognee |
| Timeline(时间线) | 按时序排列的事件流 | 时序查询自然 | 检索效率待优化 | MemU |
| Hierarchy(层级) | OS 式分层(核心/召回/归档) | 精细控制上下文 | 设计复杂 | MemGPT/Letta |
Schema 策略对比:
| 策略 | 代表方案 | 优缺点 |
|---|---|---|
| 全预定义 | MemU、Memobase | 可控、省 token、但不灵活 |
| 全动态 | Mem0 | 灵活但难查询,依赖 LLM 判断质量 |
| 混合 | A-Mem、Echo | 预定义核心 + 运行时扩展,平衡可控性和灵活性 |
2.3 开源框架详解
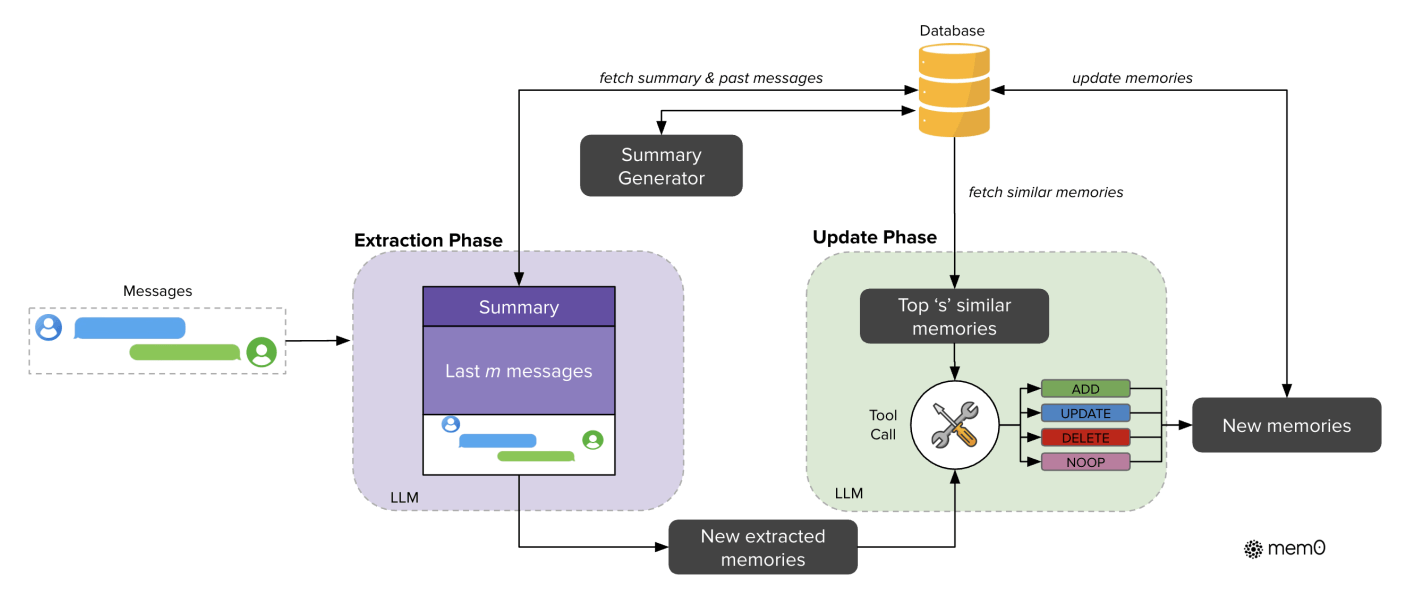
Mem0:两阶段提取-去重管线
核心算法:
Phase 1 - 提取:
输入 = 最新消息对 + 最近 m 条消息 + 滚动摘要
→ MEMORY_DEDUCTION_PROMPT → LLM 提取候选 facts 列表
→ 每条 fact 计算 embedding
Phase 2 - 去重更新:
对每条候选 fact:
→ 向量搜索 top-k 相似已有记忆
→ UPDATE_MEMORY_PROMPT 输入(新fact + 已有记忆)
→ LLM 返回操作:ADD / UPDATE / DELETE / NOOP
→ 向量存储和图存储通过 ThreadPoolExecutor 并行写入
三个核心 Prompt(mem0/configs/prompts.py):
- MEMORY_DEDUCTION_PROMPT(提取):“You are a Personal Information Organizer… Extract relevant pieces of information from conversations and organize them into distinct, manageable facts… GENERATE FACTS SOLELY BASED ON THE USER’S MESSAGES.”
- UPDATE_MEMORY_PROMPT(去重):“You are a smart memory manager… You can perform four operations: (1) add, (2) update, (3) delete, (4) no change.”
- Response Prompt(检索应答):引导 LLM 基于已有记忆回答问题
Graph Memory (Mem0g):并行运行实体提取(EXTRACT_ENTITIES_TOOL)和关系提取(RELATIONS_TOOL),生成 (source, relationship, destination) 三元组写入 Neo4j
代码示例:
from mem0 import Memory
config = {
"graph_store": {
"provider": "neo4j",
"config": {"url": "bolt://localhost:7687", "username": "neo4j", "password": "pwd"},
},
}
m = Memory.from_config(config_dict=config)
# 写入(触发 extract → dedup → store 全流程)
m.add("I love hiking and I'm planning to visit Paris next month.", user_id="alice")
# 检索(向量搜索 + 图搜索并行)
results = m.search("What are Alice's travel plans?", user_id="alice")数据结构:
- Vector Store:
{id: UUID, memory: str, hash: str, metadata: dict, embedding: list[float], user_id, created_at, updated_at} - Graph Store: Nodes =
{name, type, embedding}, Edges ={source, relationship, destination} - History: 每次 ADD/UPDATE/DELETE 操作都记录
{memory_id, old_memory, new_memory, event, timestamp}
Memobase:基于 Profile 的结构化记忆
GitHub | 超越 RAG:Memobase 为 AI 应用注入长期记忆
核心特点:不依赖 embedding 做检索,用 SQL 查 profile。
数据流:
ChatBlob 输入 → Buffer 累积 (1024 tokens / 1h 空闲)
→ Flush 触发 3 次 LLM 调用:
1. 从对话提取结构化 profile facts
2. 与已有 profile 槽位合并/冲突消解
3. 生成事件时间线条目
→ 写入 PostgreSQL
Profile Schema:
# 预定义 Schema
default_profiles:
- topic: "basic_info"
sub_topics: [name, age, gender]
- topic: "work"
sub_topics: [title, company, industry]
# 可自定义扩展
additional_user_profiles:
- topic: "Gaming"
sub_topics: ["FPS", "LOL"]存储结构(PostgreSQL):
CREATE TABLE user_profiles (
id UUID, project_id VARCHAR, user_id VARCHAR,
topic VARCHAR, -- 'basic_info'
sub_topic VARCHAR, -- 'name'
content TEXT, -- 'Gus'
created_at TIMESTAMP, updated_at TIMESTAMP,
PRIMARY KEY (id, project_id)
);代码示例:
from memobase import MemoBaseClient, ChatBlob
client = MemoBaseClient(project_url="http://localhost:8019", api_key="secret")
uid = client.add_user()
u = client.get_user(uid)
blob = ChatBlob(messages=[
{"role": "user", "content": "I'm Gus, 25, working as a software engineer at Google."},
{"role": "assistant", "content": "Nice to meet you, Gus!"},
])
u.insert(blob)
u.flush(sync=True) # 触发 LLM 提取
profile = u.profile(need_json=True)
# => {"basic_info": {"name": {"content": "Gus"}}, "work": {"title": {"content": "Software Engineer"}}}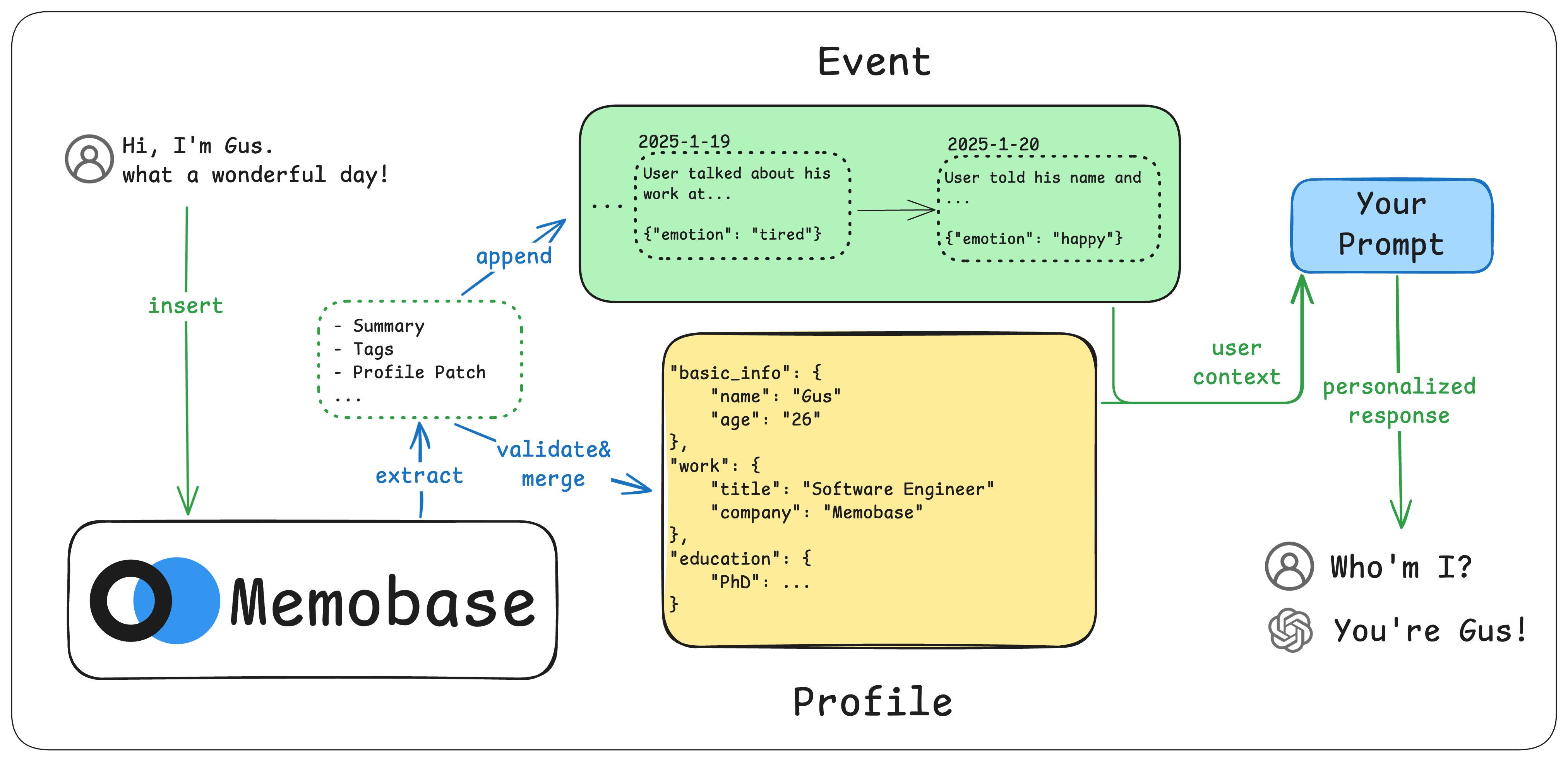
MemGPT / Letta:操作系统式记忆层级
三层记忆 = OS 虚拟内存:
| 层级 | OS 类比 | 描述 | 访问方式 |
|---|---|---|---|
| Core Memory | RAM | 固定大小,始终在 prompt 中。agent 通过 tool call 读写 | 直接可见 |
| Recall Memory | Disk (日志) | 完整对话历史,可搜索但不在上下文中 | conversation_search(query) |
| Archival Memory | Disk (知识库) | 向量索引的长期知识,无限大小 | archival_memory_search(query) |
关键创新:agent 自编辑记忆。LLM 完全通过 tool call 操作——连发消息都需要调用 send_message():
# Core Memory 工具
memory_replace(section, old_str, new_str) # 替换记忆块中的文本
memory_rethink(section, new_content) # 重写整个记忆块
archival_memory_insert(content) # 持久化事实到向量库
archival_memory_search(query, page) # 搜索归档记忆上下文溢出处理算法:
- 对话历史超出窗口 → 驱逐最早一批消息
- LLM 从「已有滚动摘要 + 被驱逐消息」生成递归摘要
- 新摘要替换旧摘要注入 prompt
- 被驱逐消息存入 Recall Storage 保持可搜索
Heartbeat 机制:每次 tool call 后可设置 request_heartbeat=True 让 agent 立即再次调用自己,实现无需用户输入的多步推理链。
from letta import create_client
client = create_client()
agent = client.create_agent(
name="my_agent",
memory=ChatMemory(
persona="I am a helpful assistant.",
human="Alice is a software engineer.", # Core Memory: human block
),
)
# 对话中 agent 自动编辑 Core Memory
response = agent.send_message("I just switched to product management.")
# agent 内部调用: memory_replace("human",
# "Alice is a software engineer.",
# "Alice recently switched from software engineering to product management.")A-Mem:Zettelkasten 式自组织记忆图
记忆笔记数据结构:
m_i = {c_i, t_i, K_i, G_i, X_i, e_i, L_i}
c_i = 原文内容 K_i = LLM 生成关键词 e_i = 嵌入向量
t_i = 时间戳 G_i = LLM 生成标签 L_i = 链接集合
X_i = LLM 生成上下文描述
三阶段算法:
Phase 1 - 笔记构建:
输入原文 c_i → LLM 生成 K_i, G_i, X_i → 计算 e_i = embed(c+K+G+X) → L_i = {}
Phase 2 - 链接生成:
计算 e_i 与所有已有记忆的 cosine 相似度 → 取 top-k
→ 对每个候选: LLM 判断是否存在有意义的关联(因果、概念、模式)
→ 若是: 建立双向链接 L_i.add(neighbor_id), L_neighbor.add(i)
Phase 3 - 记忆演化:
对每个新链接的历史记忆 → LLM 评估新记忆是否改变其含义
→ 若是: 更新历史记忆的 X, K, G(记忆网络自我精炼)
检索时的「激活扩散」:查询命中记忆后,自动沿 L_i 链接扩展检索关联记忆,模拟 Zettelkasten 的「顺藤摸瓜」。
与 Mem0 的关键差异:Mem0 有固定的 ADD/UPDATE/DELETE 操作流水线;A-Mem 让 agent 在每一步自主决策更新什么、链接什么、如何演化——更高的自主性但也更高的 LLM 调用成本。
LangMem:LangGraph 生态的记忆层
三种记忆类型:
- Semantic:事实和知识 → Collections / Profiles 存储
- Episodic:过去的交互经历 → Collections + 时间戳
- Procedural:行为规则 → 更新 agent 的 system prompt(Prompt Optimizer)
两种实现模式:
# 模式 1: Hot Path(实时,agent 通过 tool call 管理记忆)
from langmem import create_manage_memory_tool, create_search_memory_tool
from langgraph.prebuilt import create_react_agent
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(index={"dims": 1536, "embed": "openai:text-embedding-3-small"})
agent = create_react_agent(
"anthropic:claude-sonnet-4-20250514",
tools=[
create_manage_memory_tool(namespace=("memories", "{user_id}")),
create_search_memory_tool(namespace=("memories", "{user_id}")),
],
store=store,
)
# 模式 2: Background(异步,对话结束后反思提取)
from langmem import create_memory_store_manager, ReflectionExecutor
manager = create_memory_store_manager(
"anthropic:claude-sonnet-4-20250514",
query_model="anthropic:claude-haiku-4-5-20251001", # 查询用便宜模型
namespace=("memories", "{user_id}"),
schemas=[UserPreference], # 可选 Pydantic Schema
enable_inserts=True, enable_deletes=True,
)
reflection = ReflectionExecutor(manager, store=store)Prompt Optimizer(程序记忆):通过 meta-prompt 自动从对话反馈中学习行为规则,写入 agent 的 system prompt。
Zep (Graphiti):时序知识图谱
三层图架构 G = (N, E, φ):
| 子图 | 内容 | 特点 |
|---|---|---|
| Episode Subgraph | 原始消息/事件节点 | 带时间戳的原始语料,ground truth |
| Semantic Entity Subgraph | 实体节点 + 关系边 | LLM 提取的知识层,边带时间有效期 |
| Community Subgraph | 实体聚类的社区节点 | Label Propagation 算法检测,高层摘要 |
Episode 处理 8 步管线:
1. 实体提取 (LLM + 反思去幻觉) → 计算 1024 维 embedding
2. 实体候选搜索 (cosine + BM25 混合搜索)
3. 实体消解 (LLM 判断是否重复,合并)
4. 图写入 (Neo4j Cypher 操作)
5. 事实提取 (LLM 提取实体间的原子命题,带 valid_at/invalid_at)
6. 边去重 (限定在同一实体对之间搜索相似边,LLM 决定插入/更新/失效)
7. 社区检测 (Label Propagation)
8. 时间维护 (双时间线: valid_at/invalid_at + created_at/expired_at)
时间感知的边数据结构:
EntityEdge(
name="works_at",
fact="Alice works at Google",
source_node_uuid="...", target_node_uuid="...",
created_at=datetime(2024, 3, 15), # 系统学到这个事实的时间
valid_at=datetime(2020, 6, 1), # Alice 实际入职时间
invalid_at=datetime(2024, 1, 15), # Alice 实际离职时间
episodes=["ep_001", "ep_042"], # 来源 episode
)三路混合检索(Reciprocal Rank Fusion):
φ_cos— cosine 语义相似度φ_bm25— BM25 全文检索φ_bfs— 广度优先图遍历
from graphiti_core import Graphiti
from graphiti_core.nodes import EpisodeType
graphiti = Graphiti("bolt://localhost:7687", "neo4j", "password")
# 添加 episode(触发完整的 8 步管线)
await graphiti.add_episode(
name="conversation", episode_body="Alice left Google to join Anthropic.",
episode_type=EpisodeType.text, reference_time=datetime(2024, 1, 15),
)
# 时间感知检索
results = await graphiti.search("Where does Alice work?")
# 返回带 valid_at/invalid_at 的时间线MemU:为主动式 Agent 设计的层级文件系统
三层层级架构(类似文件系统):
Layer 3: MemoryCategory (文件夹)
├── personal_info/, preferences/, relationships/, knowledge/
├── routines/, goals/, experiences/, skills/, tools/, context/
Layer 2: MemoryItem (文件) — 最小语义单元, 可属于多个 Category
Layer 1: Resource (挂载点) — 原始数据: 对话/文档/图片/视频
强化机制:
class MemoryItem:
memory_type: str # profile/event/skill/tool
summary: str
reinforcement_count: int # 重复提及时 +1
salience_score: float # = log(1 + count)第 1 次提到 → 创建 Item, count=1;重复提到 → count++, 更新 last_reinforced_at
2.4 框架对比总表
| 框架 | 记忆模型 | 存储后端 | 去重策略 | 时间感知 | 核心创新 |
|---|---|---|---|---|---|
| Mem0 | Vector + Graph | 任意向量库 + Neo4j | LLM 决定 ADD/UPDATE/DELETE/NOOP | 元数据时间戳 | 3 个 prompt 驱动的两阶段管线 |
| Memobase | 结构化 Profile | PostgreSQL + Redis | LLM 合并到 profile 槽位 | 事件时间线 | 无 embedding 检索,SQL 读取 <100ms |
| MemGPT/Letta | 3 层层级 | 任意向量库 | agent 通过 tool call 自管理 | 对话时间戳 | OS 式虚拟上下文,agent 自编辑 |
| A-Mem | Zettelkasten 笔记图 | ChromaDB | LLM 驱动链接 + 演化 | 笔记时间戳 | 自主记忆演化,激活扩散检索 |
| LangMem | Semantic/Episodic/Procedural | LangGraph BaseStore | LLM 决定 create/update/delete | N/A | Prompt 优化即程序记忆 |
| Zep | 3 层时序知识图谱 | Neo4j | 实体/边消解 + 时间失效 | 双时间线 (valid_at + created_at) | 8 步管线,时间感知 RRF 检索 |
| MemU | 层级文件系统 | 内存/文件 | 强化计数去重 | 事件时间线 | salience_score 强化机制 |
2.5 研究前沿
记忆内化:从外挂到模型能力
- Google Titans:self-attention 为「短期系统」,独立神经长期记忆模块跨越上下文窗口
- Deepseek Engram:将实体知识直接注入模型参数,增加模型等效深度
- Minimax:引入独立记忆层管理长期知识,先解决「装不装得下」再讨论「该不该留下来」
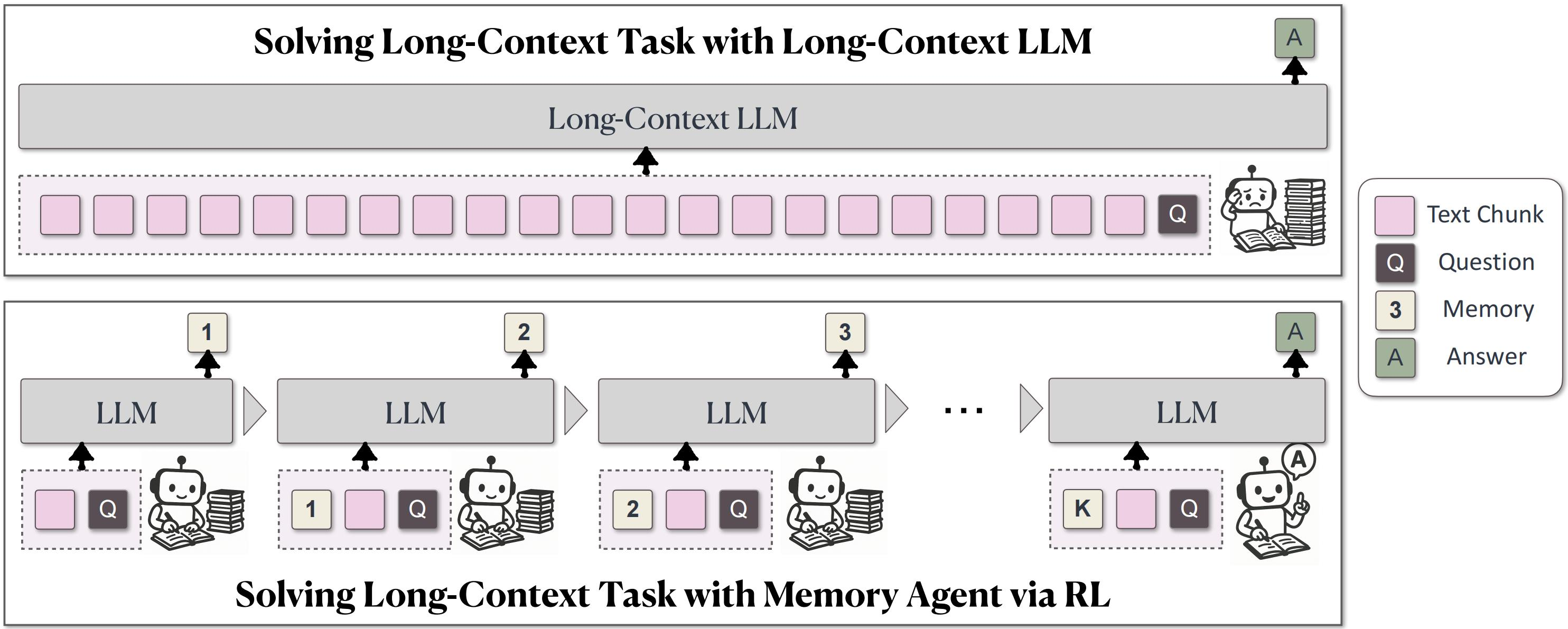
RL 与记忆的融合
启发式规则 → Prompt 驱动 → RL 辅助 → 完全 RL 驱动
(手写规则) (LLM判断) (Mem-α) (Memory-R1, 未来)
- 字节 MemAgent:通过 RL 训练模型在超长上下文中「学会取舍」,主动形成记忆习惯
- Mem-α:RL 自动化记忆写入,但检索仍依赖手动 pipeline
- 理想目标:agent 自主发明记忆格式和管理策略,而非依赖人类设计的认知类比
其他前沿方向
- 多模态记忆:视觉/音频信号的存储与检索(CoMEM、Mem2Ego)
- 多 agent 共享记忆:从孤立记忆到共享认知基底,需解决写冲突、权限控制(G-Memory)
- 世界模型中的记忆:记忆成为世界模型保持时间一致性的核心机制(State-Space Models、UniWM)
- 可信记忆:隐私保护(差分隐私、记忆编辑)、可解释性(溯源路径)、幻觉鲁棒性(冲突检测)
3. 应用层 / 产品层
3.1 对话型 Agent 的记忆实践
ChatGPT Memory
- 机制:内部称为 “bio tool”。自动从对话中提取事实,存储为带时间戳的 key-value 对,注入到 system prompt 的
Model Set Context段。不是 RAG——没有向量数据库,所有记忆直接拼接进 prompt - 提取:模型自主判断哪些信息值得保存。用户也可显式说 “Remember that…”。触发保存时内部标记 “Model set context updated”
- 记忆满时:自动优先级管理——根据 recency(最近性)和 frequency(频率)决定保留哪些记忆
- 作用域:全局 + 项目级(2025.8 新增 Project-only memory)
- Chat History Reference(Plus/Pro):2025 年新增,可引用所有历史对话内容,不限于显式保存的记忆
- 安全风险:Simon Willison 警告其为 “持久化 prompt 注入攻击的载体”。研究者演示 “ZombieAgent” 攻击——通过文件附件植入恶意记忆指令
- 用户控制:查看/编辑/删除单条记忆,对话中说 “forget this”,全局开关
Claude Memory
- 机制:自动生成结构化 markdown 格式的 Memory Summary,按 “Role & Work”、“Current Projects”、“Personal Context”、“Communication Style” 等类别组织
- 触发:约 10,000 tokens 后首次提取,之后每 5,000 tokens 或每 3 次 tool call 更新。每 24 小时跨会话综合更新
- 存储:人类可读的纯文本文件,用户可直接查看和编辑——刻意的透明性设计
- 作用域:全局 + 项目级(每个项目独立记忆空间和摘要)
- 记忆迁移(2026.3):支持从 ChatGPT/Gemini 导入对话历史,自动构建用户画像
- 用户控制:查看完整文本 / 直接编辑 / 暂停(保留但停止更新) / 完全删除
Google Gemini
- 机制:将所有记忆整合为一份结构化文档
user_context——带分节的事实要点大纲,是唯一的长期记忆制品 - 结构:固定 schema 分节——人口统计信息、兴趣偏好、时间标注(“considering a move to SF (updated June 2024)” 会被解读为历史上下文而非当前意图)、显式用户指令
- 检索:
user_context文档 + 最近对话轮次(上次摘要后的原始消息)直接注入 prompt - Gems:预配置的自定义助手,有固定指令和上传知识但没有跨会话记忆
- 用户控制:查看/编辑/删除 Saved Info。回答使用了记忆时显示 “Used your saved info” 标识
- 设计取舍:Shlok Khemani 分析指出,尽管 Google 拥有海量用户数据,Gemini “barely uses it”——记忆系统刻意与 Google 数据基础设施隔离,优先隐私而非个性化深度
产品对比
| 维度 | ChatGPT | Claude | Gemini |
|---|---|---|---|
| 存储格式 | key-value + 时间戳 | 结构化 markdown 文档 | 结构化 user_context 文档 |
| 自动提取 | 是 | 是 | 是 |
| 用户可编辑 | 单条编辑/删除 | 直接编辑完整文本 | 单条编辑/删除 |
| 透明度 | 较低(prompt 注入不可见) | 高(纯文本可见) | 中 |
| 作用域 | 全局 + 项目 | 全局 + 项目 | 全局 |
| 记忆过期 | 自动优先级排序 | 手动管理 | 永久(除非手动删除) |
3.2 代码助手的记忆实践
GitHub Copilot Memory
- 核心创新:基于引用的验证。每条记忆都关联到具体代码位置(citation),应用前实时验证引用:
- 检查引用的代码位置是否仍存在
- 验证信息与当前分支是否一致
- 若代码与记忆矛盾,存储修正版本
- 跨功能共享:coding agent 发现的模式,code review 可以直接使用(反之亦然)
- 自动过期:28 天后自动失效,防止陈旧上下文。激进但有效避免了其他系统的”过时记忆”问题
- 安全性:Citation 验证机制直接应对了 ChatGPT 面临的 memory poisoning 攻击
Claude Code
双层记忆系统(手动 + 自动):
- CLAUDE.md(手动):用户编写的项目指令文件。从工作目录向上搜索到根目录,加载沿途所有
CLAUDE.md和CLAUDE.local.md。推荐 30-100 行 - MEMORY.md(自动):存储在
~/.claude/projects/<project>/memory/MEMORY.md。agent 自身在会话中写入——记录反复出现的模式、纠正的错误、观察到的偏好。前 200 行在会话开始时加载
Cursor
- 完全手动配置的 rule 文件:
.cursor/rules/*.mdc - 每个 rule 文件包含描述、Glob 匹配模式、
alwaysApply标志 - 没有自动学习/提取——完全用户控制,可预测但需要显式配置
3.3 其他产品形态
Notion AI(Workspace-as-Memory)
Notion 工作区本身就是记忆。AI 索引所有页面和数据库,通过 AI Connectors 整合 Slack、Google Drive、Jira 等外部数据(只读,初次同步最长 72 小时)。不做隐式偏好学习——只知道工作区中明确记录的内容。
Replit Agent(Checkpoint + 压缩)
采用 checkpoint 机制(类似 git commit + 数据库快照)+ LLM 驱动的记忆压缩。在多 agent 架构(manager/editor/verifier)中,跨 agent 跳转时压缩记忆,任务完成后仅保留高层描述。发现:长轨迹会导致复合型模型错误,因此让执行环境本身引导 agent 而非纯依赖记忆。
Character.ai(最受限的记忆)
- Chat Memories:固定文本框(400 字符 / 付费用户 2250 字符)
- Pinned Memories:手动 pin 最多 15 条消息
- 记忆按用户-角色关系隔离——一个角色不会从所有用户交互中全局学习,防止人格漂移
- 优先保留情感显著或高频引用的信息
3.4 不同场景的记忆侧重
| 场景 | 记忆重点 | 记忆类型 |
|---|---|---|
| 代码助手 | 项目上下文、代码库结构、命名风格、常用框架 | Factual(环境) + Experiential(技能) |
| 智能客服 | 用户历史问题、解决方案记录、服务配置 | Factual(用户) + Experiential(案例) |
| 个人助理 | 日程、目标、行为模式、通知偏好 | Factual(用户) + Working |
| 推荐系统 | 显式/隐式反馈、兴趣档案、行为轨迹 | Factual(用户) + Experiential(策略) |
| 学习应用 | 知识掌握度、学习路径、薄弱点、词汇记忆 | Factual(用户) + Experiential(案例) |
3.5 产品层的关键思考
设计维度的取舍谱:
| 维度 | 一端 | 另一端 | 趋势 |
|---|---|---|---|
| 透明度 | Claude Code(纯文本文件) | ChatGPT(不可见的 prompt 注入) | 趋向透明 |
| 隐式 vs 显式 | ChatGPT/Gemini(自动学习) | Cursor(完全手动配置) | 混合 |
| 验证 | GitHub Copilot(citation 验证) | 大多数产品(无验证) | 趋向验证 |
| 安全性 | Copilot(28 天过期+验证) | ChatGPT(已知 prompt 注入风险) | 趋向安全 |
| 作用域 | 全局记忆 | Notion(workspace 即记忆) | 分层作用域 |
关键认知:
- “从流量入口到信任入口”:记忆让用户产生「被理解」的感觉,建立长期粘性
- 记忆的透明性和可控性是用户信任的基础
- 安全不是可选项——记忆是 prompt 注入攻击的持久化载体
- 记忆提取需要 LLM 调用,存储和检索有持续成本,需要精细的成本控制
4. Benchmark 与评估
4.1 主要 Benchmark
| Benchmark | 评估维度 | 特点 |
|---|---|---|
| LoCoMo | 长对话中的记忆检索与问答 | 多轮对话场景,支持 BLEU + LLM 评估 |
| LongMemEval | 长期记忆的五大能力 | 信息提取、多会话推理、时序理解、知识更新、拒答 |
| MemBench | 记忆的保持和检索准确性 | 控制实验场景,精确测量 |
| MemoryBench | 基于真实 LLM 交互的记忆测试 | 多用户多场景,覆盖提取-检索-应用全链路 |
| MemoryAgentBench | Agent 记忆的管理与应用 | 评估记忆的读写操作和任务完成效果 |
| StreamBench | 流式交互中的持续学习 | 在线场景,评估记忆随时间的演化能力 |
| PersonalLLM | 个性化记忆与推荐 | 基于真实用户偏好数据 |
| Evo-Memory | agent 连续任务中的经验提炼与复用 | 模型是否能在连续任务中提炼经验并用上 |
4.2 评估方法
典型评估流程:
- 使用数据集初始化记忆体(根据不同方案构建不同形态的记忆)
- 使用标准化的问题集,对不同记忆体采用相同 Prompt 和 LLM 生成回复
- 评估指标:
- 自动指标:BLEU、ROUGE、F1
- LLM-as-judge:让 LLM 对比生成回复与标准答案
- 任务完成率:在下游任务中使用记忆的实际效果
已有 benchmark 上的参考成绩:Zep 在 Deep Memory Retrieval (DMR) benchmark 上达到 94.8%,MemGPT 93.4%。
4.3 开放挑战
- 缺乏统一的跨框架评估标准
- 现有 benchmark 多侧重文本记忆,多模态记忆评估几乎空白
- 长时间尺度(天/周/月级别)的记忆演化评估仍然困难
- 记忆的可信赖性(隐私、幻觉、可解释性)缺乏系统性评估方案
- 大多数 benchmark 在受控环境中测试,与真实产品场景仍有 gap
参考
综述论文
- Yuyang Hu et al. Memory in the Age of AI Agents: A Survey — Forms, Functions and Dynamics. arXiv:2512.13564, 2026.
开源框架
- Mem0 — Paper — Mem0: How Three Prompts Created a Viral AI Memory Layer
- Memobase — 官方:超越 RAG
- MemGPT/Letta — Paper
- A-Mem — Paper
- LangMem — Conceptual Guide
- Zep/Graphiti — Paper
- MemU | MemoryOS | Cognee
产品参考
- OpenAI Memory FAQ — Embrace The Red: Deep Dive
- Claude Memory Help Center
- GitHub Copilot Memory
- Shlok Khemani: Google Has Your Data, Gemini Barely Uses It
其他