算法面试通关40讲_算法面试_LeetCode刷题-极客时间 数据结构与算法之美_算法实战_算法面试-极客时间
大纲图

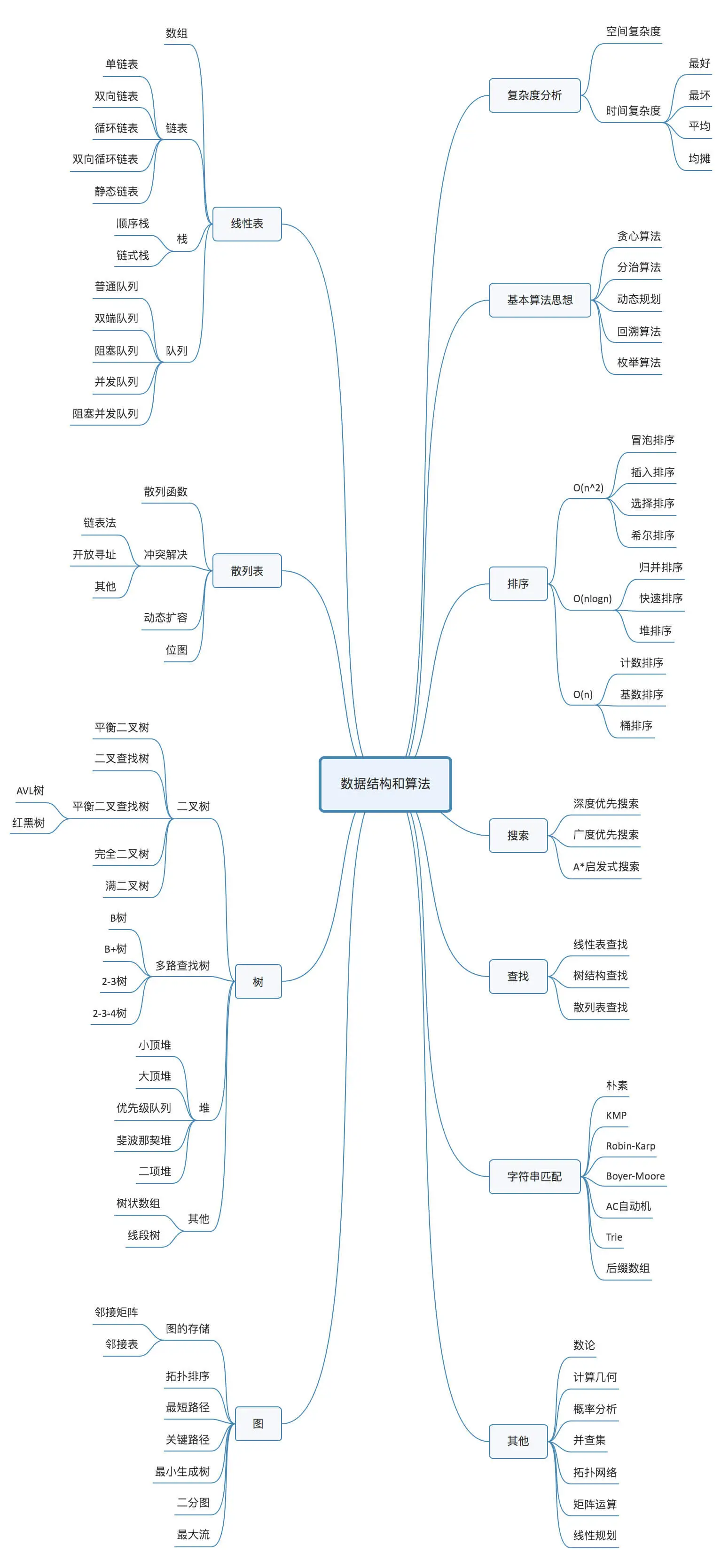
复杂度分析
- 多项式量级
- O(1)
- O(logn)
i=1; while (i <= n) { i = i * 2; }
- O(n) O(m+n)
- O(nlogn)
- O(n^2), O(n^3), O(n^k)
- 非多项式量级(NP 问题,Non-Deterministic Polynomial,非确定多项式)
- 指数阶 O(2^n) e.g. 斐波拉契数组的递归程序
- 阶乘阶 O(n!)
- 最好、最坏、加权平均复杂度、均摊时间复杂度(摊还分析)
- 主定理 Master theorem 主定理 - 维基百科,自由的百科全书
- 常见递推类算法时间复杂度:
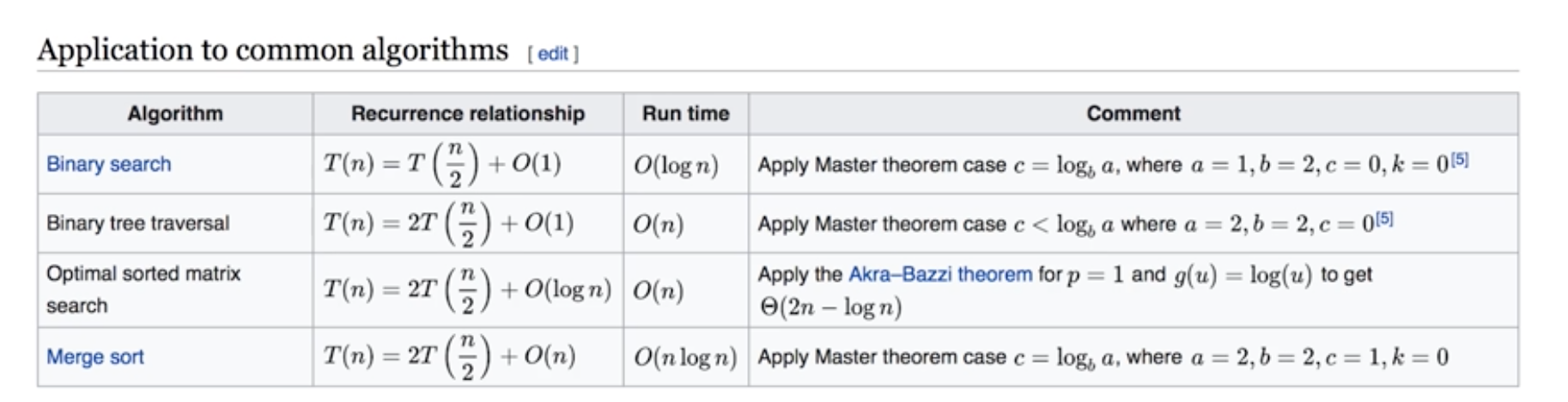
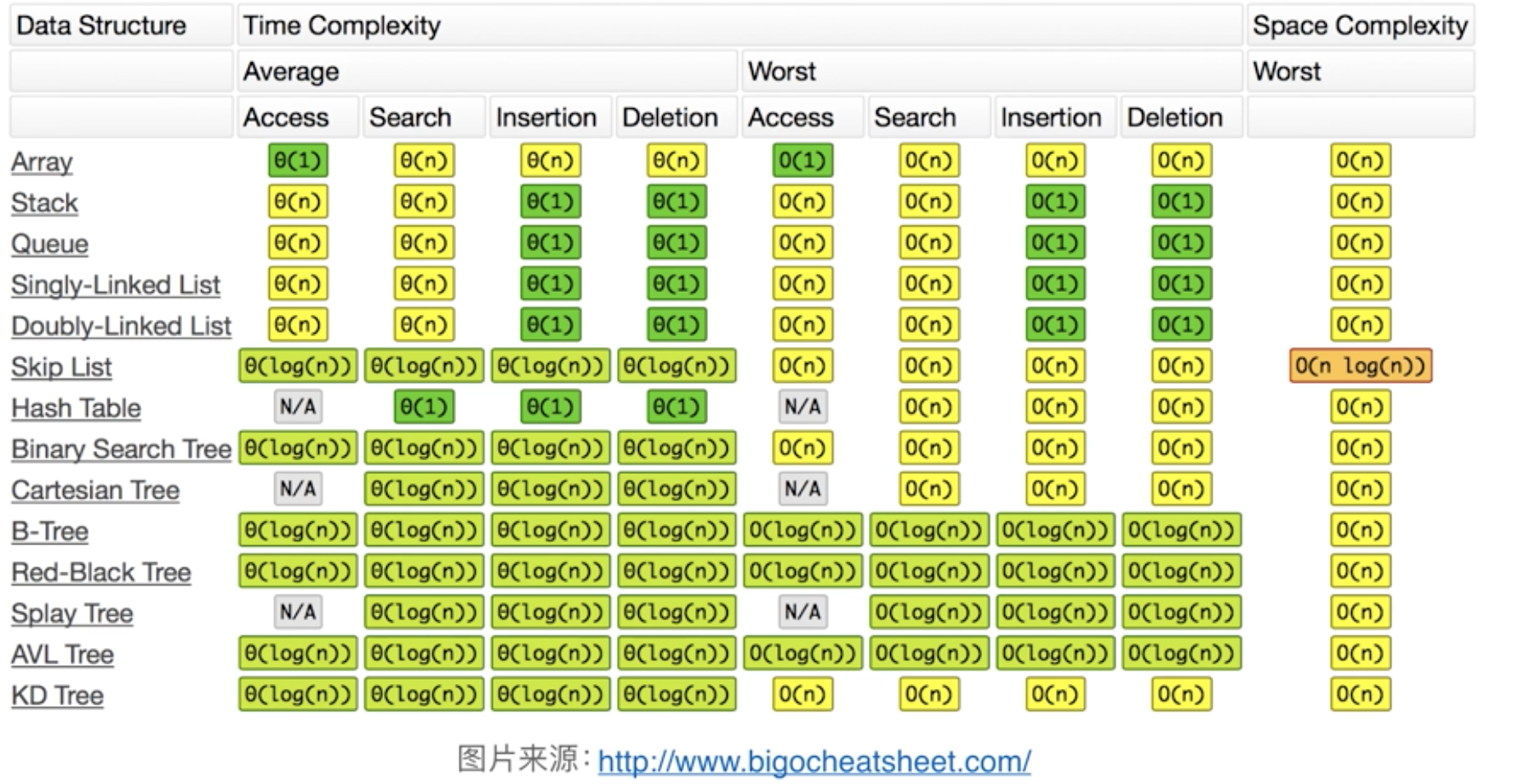
- 常见递推类算法时间复杂度:
数据结构
线性表
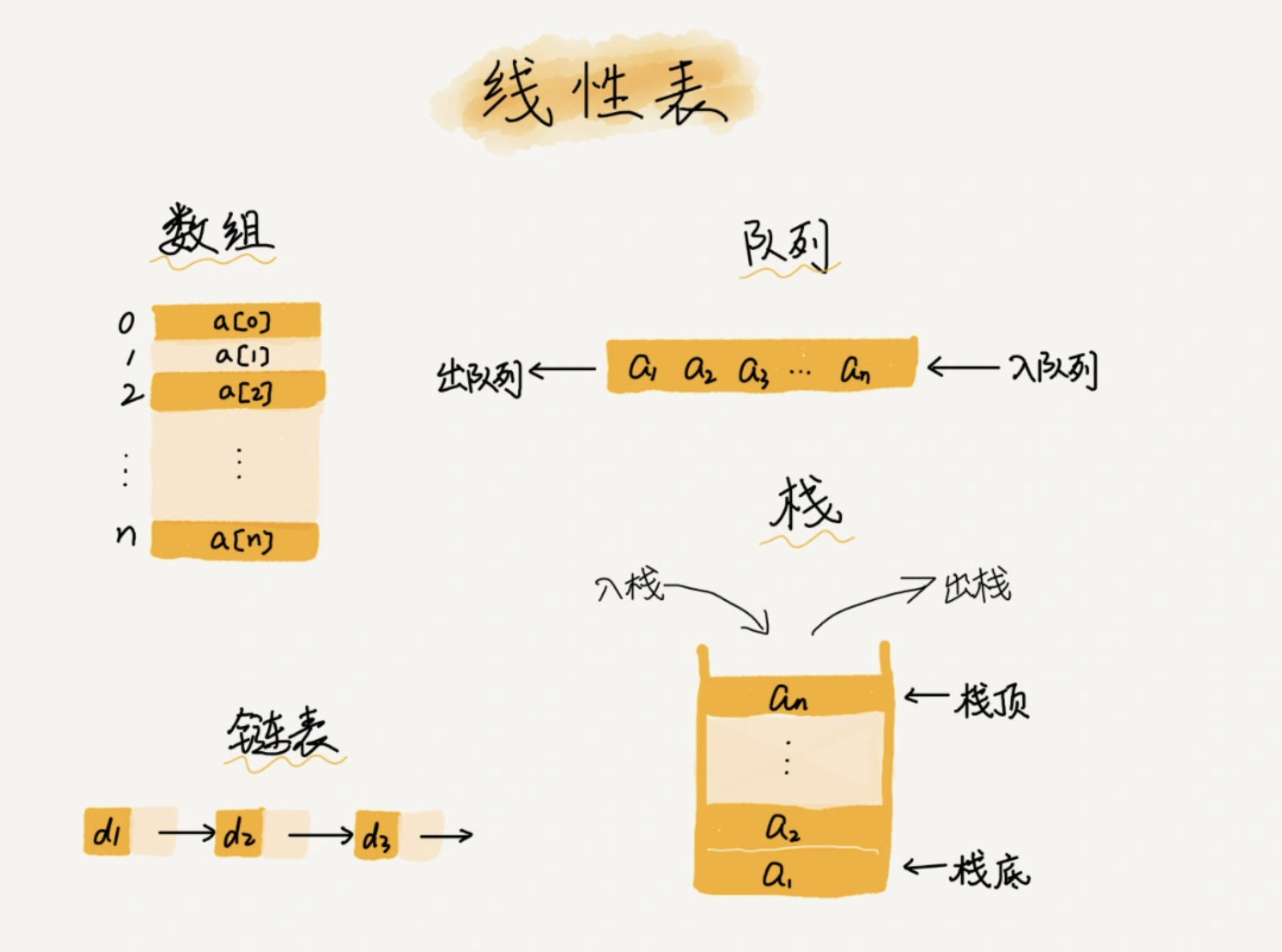
数组
- 连续的内存空间和相同类型的数据
- 支持随机访问:通过地址来访问内存中的数据,因此可以通过下标随机访问 O(1)
- 但要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据搬移工作 O(n)
- 为了避免大量数据搬移工作,在插入时,如果不需要保持原数组数据顺序,可以替换原位置数据,原位置数据移到数组末尾
- 删除时可以标记删除位,等达到某个值后再实际操作删除
- 容器(例如 Java ArrayList,c++ vector) 是对数组的封装,支持动态扩容(有一定性能损耗)
链表 Linked list
- 链表不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。每个链表的结点除了存储数据之外,还需要记录链上的下一个结点的地址
- 插入删除 O(1),随机访问 O(n)
- 适合插入/删除操作比较多或不限元素数目的
- 对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片,如果是 Java 语言,就有可能会导致频繁的 GC(Garbage Collection,垃圾回收)
- 数组在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
- CPU 在从内存读取数据的时候,会先把读取到的数据加载到 CPU 的缓存中(为了弥补内存访问速度过慢与 CPU 执行速度快之间的差异而引入)。而 CPU 每次从内存读取数据并不是只读取那个特定要访问的地址,而是读取一个数据块并保存到 CPU 缓存中,然后下次访问内存数据的时候就会先从 CPU 缓存开始查找,如果找到就不需要再从内存中取。 对于数组来说,存储空间是连续的,所以在加载某个下标的时候可以把以后的几个下标元素也加载到CPU缓存这样执行速度会快于存储空间不连续的链表存储。
- 单链表:尾结点指针不是指向下一个结点,而是指向一个空地址 NULL,表示这是链表上最后一个结点
- 双向链表:每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点
- 对于“删除给定指针指向的结点”“在给定指针前插入数据” 都只需要 O(1),而单链表需要 O(n)
- 循环链表:尾结点指针是指向链表的头结点
- 从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表;
- 缓存淘汰策略:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)
- LRU 可以用单链表实现,维护一个有序单链表,越靠近链表尾部的结点是越早之前访问的,复杂度为 O(n)(需要遍历链表查找),可以使用 Hash table 记录每个数据的位置改进到 O(1)
- 写链表代码的技巧
- 理解指针:指针存储了变量的内存地址,指向了变量
- 警惕指针丢失和内存泄漏
- 链表常见边界条件考虑:空链表,链表只有一个节点,链表只有两个节点,代码处理头节点和尾节点
- 利用哨兵节点简化实现难度
- 不带头链表:head=null 表示链表中没有结点 (head 是头节点指针,指向链表中的第一个结点)
- 带头链表:不管链表是不是空,head 指针都会一直指向这个哨兵结点。哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。

- 🚩 常见链表操作 & 常见题
- 反转链表
- Reverse Linked List - LeetCode
- 链表反转详解-CSDN博客
- Swap Nodes in Pairs - LeetCode 局部处理 → 反转/交换 → 拼接前后(局部(小片段)操作 + 把片段重新拼回大链表)
- 每次循环就是 交换 cur 和 cur.next
- 用
pre把上一组的尾巴接到这一组的头(保证链表不会断,用pre记录“反转好的前半部分”,最后拼起来 ) - 更新指针继续往后走
- 链表中环的检测:解法1 用 set 标记走过的节点,判重;解法2 快慢指针,快指针走2步,慢指针走1步,如果相遇则有环
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
- 约瑟夫问题 (循环链表)
- 判断一个字符串是否是回文字符串
- LRU
- Reverse Nodes in k-Group - LeetCode
- 反转链表
栈
- 当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。
- 栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
- 函数调用栈:操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
- 为什么用栈保存函数的局部变量?函数调用符合后进先出的特性 — 从调用函数进入被调用函数,对于数据来说,变化的是什么呢?是作用域。所以根本上,只要能保证每进入一个新的函数,都是一个新的作用域就可以。而要实现这个,用栈就非常方便。在进入被调用函数的时候,分配一段栈空间给这个函数的变量,在函数结束的时候,将栈顶复位,正好回到调用函数的作用域内。
- 常见题目
- Backspace String Compare - LeetCode
- 编译器利用栈来实现表达式求值:用两个栈来实现表达式运算。其中一个保存操作数的栈,另一个是保存运算符的栈。我们从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
- Valid Parentheses - LeetCode
- 用栈来检查表达式中的括号是否匹配:用栈来保存未匹配的左括号,从左到右依次扫描字符串。当扫描到左括号时,则将其压入栈中;当扫描到右括号时,从栈顶取出一个左括号。如果能够匹配,比如“(”跟“)”匹配,“[”跟”]”匹配,“{”跟“}”匹配,则继续扫描剩下的字符串。如果扫描的过程中,遇到不能配对的右括号,或者栈中没有数据,则说明为非法格式。当所有的括号都扫描完成之后,如果栈为空,则说明字符串为合法格式;否则,说明有未匹配的左括号,为非法格式。
- 实现浏览器的前进后退:用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈 X 中出栈,并将出栈的数据依次放入栈 Y。当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
队列
- 先进先出
- 队列的数组实现:对于栈来说,我们只需要一个栈顶指针就可以了。但是队列需要两个指针:一个是 head 指针,指向队头;一个是 tail 指针,指向队尾。
- 随着不停地进行入队、出队操作,head 和 tail 都会持续往后移动。当 tail 移动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了 ⇒ 在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再集中触发一次数据的搬移操作
- 基于链表的队列实现方法: 入队时,tail→next= new_node, tail = tail→next;出队时,head = head→next
- 循环队列:维护 head 和 tail 指针,避免数据搬移
- 确定好队空和队满的判定条件
- 队列为空的判断条件仍然是 head == tail
- 队满时,(tail+1)%n=head --- 当队列满时,图中的 tail 指向的位置实际上是没有存储数据的。所以,循环队列会浪费一个数组的存储空间。

- 确定好队空和队满的判定条件
- 阻塞队列 --- “生产者 - 消费者模型”
- 队列为空时,取数据(dequeue)会阻塞 → 消费者必须等到生产者放入新数据。
- 队列满时,放数据(enqueue)会阻塞 → 生产者必须等到消费者取走一部分。
- 普通队列失败就失败了,阻塞队列则会 卡住等待。---- 这样生产者-消费者之间可以 异步解耦,但不会丢数据。
- 实现思路
- 加锁 + 条件变量实现
- 条件变量是线程间等待某个条件发生的机制:通常配合互斥锁(mutex)一起使用:用 mutex 保护共享状态(比如队列),用 condvar 在状态不满足时把线程睡眠,状态改变时其他线程
signal/broadcast唤醒。 - 当队列空时,
dequeue线程阻塞在条件变量notEmpty上;一旦有数据入队,就唤醒。 - 当队列满时,
enqueue线程阻塞在条件变量notFull上;一旦有位置释放,就唤醒。
- 条件变量是线程间等待某个条件发生的机制:通常配合互斥锁(mutex)一起使用:用 mutex 保护共享状态(比如队列),用 condvar 在状态不满足时把线程睡眠,状态改变时其他线程
- 信号量(semaphore)实现
- 一个信号量计数空位数(控制入队),一个计数已有元素数(控制出队)。
- 信号量不足时,线程会阻塞等待。
- 加锁 + 条件变量实现
- 并发队列
- 在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题。多线程下,多个线程会同时调用
enqueue()和dequeue(),这时要保证线程安全。 - 最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作
- 实际上,基于数组的循环队列,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因。
- 环形数组:固定大小数组 +
head和tail指针,天然适合做 bounded queue。 - CAS(Compare-And-Swap)原子操作:
- CAS 是 CPU 提供的一个原子指令:“如果内存地址的值是 A,就把它改成 B;否则不改并返回失败”。这个操作是原子的——在多核下不会被打断,也不需要内核锁。
- 很多并发算法可以用 CAS 来做乐观并发控制(optimistic concurrency)——假设冲突少,尝试做修改,如果失败就重试,而不是用锁把所有人串行化。
- 入队时,CAS 尝试更新
tail指针(如果被别的线程抢先修改,重试);出队时,CAS 尝试更新head指针
- 环形数组:固定大小数组 +
- 在多线程情况下,会有多个线程同时操作队列,这个时候就会存在线程安全问题。多线程下,多个线程会同时调用
- 应用:线程池请求排队等任何有限资源池中,用于排队请求
- 基于数组实现的有界队列(bounded queue) ,常用环形数组 ring buffer
- 一次性分配固定大小的连续内存,空间上有上限;访问元素时内存局部性好,CPU 缓存命中率高,入队出队操作快。
- 适合高性能、低延迟需求的场景。
- 大量使用在消息队列、生产者消费者、实时系统、操作系统内核缓冲区、网络 socket 缓冲、音视频播放缓冲(环形缓冲区)、多线程任务队列。
- 基于链表的无限排队的无界队列(unbounded queue), 常见单链表+头尾指针
- 适合需要动态扩容、但对性能要求没那么苛刻的情况。
- 比如普通的数据结构库、支持无限积压任务的阻塞队列。
- 基于数组实现的有界队列(bounded queue) ,常用环形数组 ring buffer
- 🚩 如何实现无锁并发队列
- 常见题目
散列表 Hash table
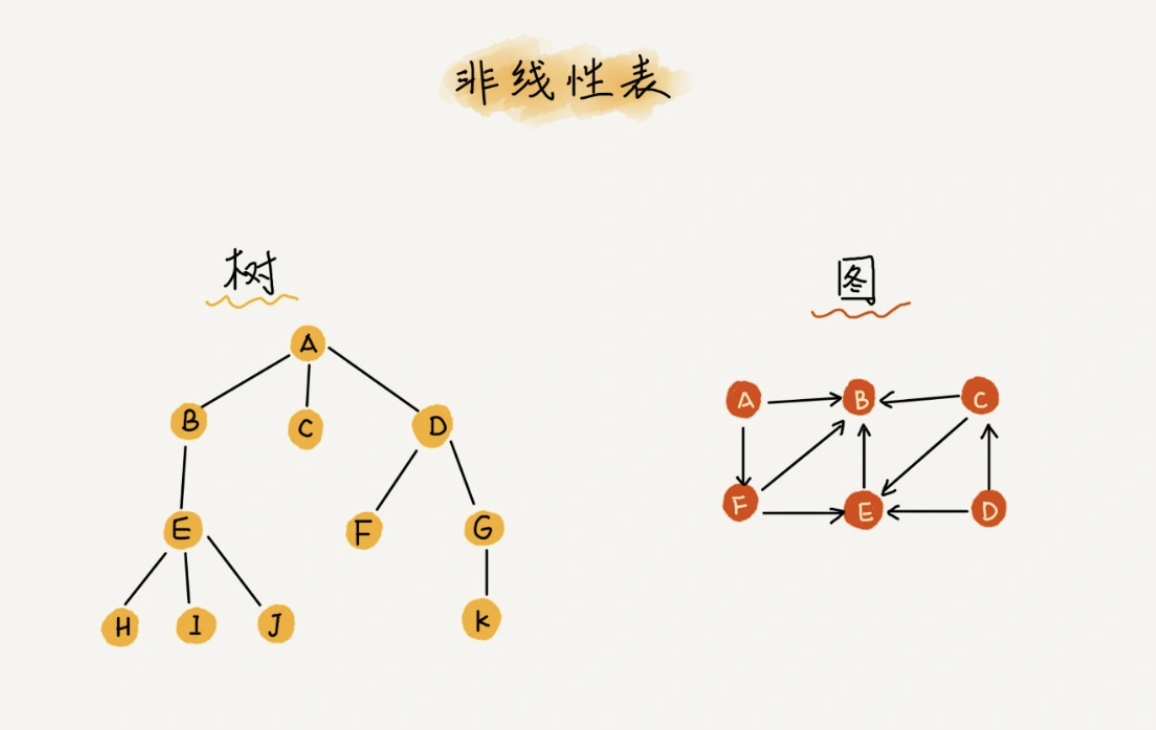
树
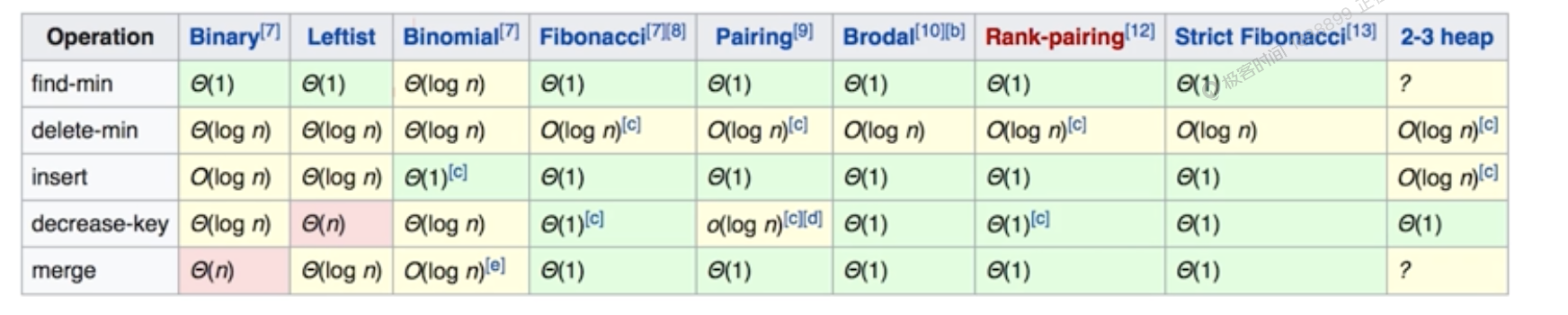
优先队列 priority queue
- 正常入,按照优先级出
- 实现机制
- 方法 1 Heap(Binary, Binomial, Fibonacci)
- 最小堆:最小的元素永远在堆顶,加入一个元素时需要调整整个二叉堆
- 堆有很多种实现方式,一般用斐波拉契堆实现,效率较好
- 方法2 Binary search tree
- 方法 1 Heap(Binary, Binomial, Fibonacci)
- 🚩 手写一个优先队列 / 二叉堆,实现插入、删除等方法
- Kth Largest Element in a Stream - LeetCode
- 思路1 维护一个包含topk 数据的数组,对数组排序。每次新进来元素更新数组,时间复杂度 O(N*K*logK)
- 🚩 思路2 维护包含 topk 的 min heap,每次进来新的元素判断是否插入 min heap 中,时间复杂度 O(N*logK)
- Sliding Window Maximum - LeetCode
- 思路1 MaxHeap :维护堆,每次移动删除离开的元素,加入新的元素,结果是堆顶元素 时间复杂度 O(N*logK)
- 思路2 使用双端队列(Deque),这是一种支持从两端进行插入和删除的队列 时间复杂度 O(N)
- 队列大小是有限的,只需要找最大值。
- 当新的元素进入窗口时,我们就从队列的尾部去除所有比新元素小的元素的索引,因为它们不再可能成为最大值。保留在队列最左端的就是最大值
图
递归
- 基本上,所有的递归问题都可以用递推公式来表示。递归问题满足的三个条件:
- 一个问题的解可以分解为几个子问题的解
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
- 存在递归终止条件
- 写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
- 如果一个问题 A 可以分解为若干子问题 B、C、D,你可以假设子问题 B、C、D 已经解决,在此基础上思考如何解决问题 A。
- 只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
- 递归代码要警惕堆栈溢出
- 函数调用会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险。
- 递归调用超过一定深度(比如 1000)之后,我们就不继续往下再递归了,直接返回报错。 --- 不能完全解决问题,因为最大允许的递归深度跟当前线程剩余的栈空间大小有关,事先无法计算
- 递归代码要警惕重复计算
- 为了避免重复计算,我们可以通过一个数据结构(比如散列表)来保存已经求解过的 f(k)。当递归调用到 f(k) 时,先看下是否已经求解过了。如果是,则直接从散列表中取值返回,不需要重复计算
- 在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据
排序
- O(n^2): 冒泡、插入、选择
- O(nlogn):快排、归并
- O(n)